Plausible values (= theta estimates with their error distributions) were first developed for the analyses of 1983-84 NAEP (National Assessment of Educational Progress) data, by Mislevy, Sheehan, Beaton and Johnson, based on Rubin's work on multiple imputations. Plausible values were used in all subsequent NAEP surveys, TIMSS and now PISA.
According to air.org:
Plausible values are imputed values that resemble individual test scores and have approximately the same distribution as the latent trait being measured. Plausible values were developed as a computational approximation to obtain consistent estimates of population characteristics in assessment situations where individuals are administered too few items to allow precise estimates of their ability. Plausible values represent random draws from an empirically derived distribution of proficiency values that are conditional on the observed values of the assessment items and the background variables.
What Plausible Values Are
The simplest way to describe plausible values is to say that plausible values are some kind of student ability estimates. There are some differences between plausible values and the θ (student ability parameter) as in the usual 1, 2 or 3-PL item response models. Instead of directly estimating a student's θ, we now estimate a probability distribution for a student's θ. That is, instead of obtaining a point-estimate for θ, we now come up with a range of possible values for a student's θ, with associated likelihood of each of these values. Plausible values are random draws from this (estimated) distribution for a student's θ (I will call this distribution "the posterior distribution").
Mathematically, we can describe the process as follows: Given an item response pattern x, and ability θ, let f(x|θ) be the item response probability, f(x|θ) could be 1, 2 or 3-PL model, for example). Further, we assume that θ comes from a normal distribution g(θ) ~ N(μ,σ²). (In our terminology, we often call f(x|θ) the item response model, and g(θ) the population model). It can be shown that, the posterior distribution, h(θ|x), is given by
![]()
That is, if a student's item response pattern is x, then the student's posterior (θ) distribution is given by h(θ|x). Plausible values for a student with item response pattern x are random draws from the probability distribution with density h(θ|x). Therefore, plausible values provide not only information about a student's "ability estimate", but also the uncertainty associated with this estimate.
If we draw many plausible values from a student's posterior distribution h(θ|x), these plausible values will form an empirical distribution for h(θ|x) (as plausible values are observations from h(θ|x). So if a data analyst is given a number of plausible values for each student, an empirical distribution of h(θ|x) can be built for that student. This is done because there is no nice closed form for h(θ|x) to give to data analysts, except for through the empirical way (plausible values) (unless you have ConQuest). Typically, 5 plausible values are generated for each student (and deemed sufficient to build an empirical distribution!)
As plausible values are random draws from a student's posterior distribution, plausible values are not appropriate to be used as individual student scores for reporting back to the students. Suppose two students have the same raw score on a test, their plausible values are likely to be different as these are random draws from the posterior distribution. Imagine the outcry if we ever give two students different ability scores when they have the same raw score. However, plausible values are used to estimate population characteristics, and they do a better job than a set of point estimates of abilities. I will give more details about this in the next section. In NAEP, TIMSS and PISA, we do not report individual scores. We only estimate population parameters such as mean, variance and percentiles.
Why We Need Plausible Values
So why are plausible values used?
(1) Some population estimates are biased when point estimates are used to construct population characteristics.
(2) Secondary data analysts can use "standard" techniques (e.g., SPSS, SAS) to analyze achievement data provided in the form of plausible values.
(3) Plausible values facilitate the computation of standard errors of estimates for complex sample designs.
Plausible Values versus Point Estimates
If we are interested in the population characteristics of some
ability, Θ, one way to go about it is to compute an estimate for
each student, ![]() , and then compute the mean, variance, percentiles,
etc. from these
, and then compute the mean, variance, percentiles,
etc. from these ![]() .
.
Consider two possible estimates for ![]() : the Maximum Likelihood
Estimate (MLE) and the Expected A-Posteriori estimate (EAP). In
the case of the 1-parameter (Rasch) model, MLEs are ability
estimates that maximise the likelihood function of response
patterns
: the Maximum Likelihood
Estimate (MLE) and the Expected A-Posteriori estimate (EAP). In
the case of the 1-parameter (Rasch) model, MLEs are ability
estimates that maximise the likelihood function of response
patterns
![]()
where i is the index over items, and n is the index over people, and xin is the item response (0 or 1) for person n on item i. We use the formula for dichotomous items, for simplicity. That is, MLE estimates only involve the item response model. There is no assumption about the population model.
Mean and Variance
It can be shown that if ![]() s are MLEs,
the mean of
s are MLEs,
the mean of ![]() is an unbiased
estimate of μ, the population mean of Θ. But the variance of
is an unbiased
estimate of μ, the population mean of Θ. But the variance of ![]() is
an over-estimate of σ², the population variance.
But if our
is
an over-estimate of σ², the population variance.
But if our ![]() s are
EAPs (e.g., ability estimates from Marginal Maximum Likelihood
MMLE models), where we assume an item response model, e.g., f(x|θ),
it can be shown that the mean of EAPs is an unbiased estimate of
the population mean, μ, but the variance of the EAPs is an
under-estimate of σ². In both the MLE and EAP cases, the bias does
not go away when the sample size increases. The bias is reduced
when the number of items increases, and can be removed by a
mathematical disattenuation.
s are
EAPs (e.g., ability estimates from Marginal Maximum Likelihood
MMLE models), where we assume an item response model, e.g., f(x|θ),
it can be shown that the mean of EAPs is an unbiased estimate of
the population mean, μ, but the variance of the EAPs is an
under-estimate of σ². In both the MLE and EAP cases, the bias does
not go away when the sample size increases. The bias is reduced
when the number of items increases, and can be removed by a
mathematical disattenuation.
One way to overcome the variance bias problem is to use the MML and
directly estimate μ and σ² without going through the step of
computing individual ![]() . This is possible with MML because we can
integrate out the ability parameter θ in the likelihood equation:
. This is possible with MML because we can
integrate out the ability parameter θ in the likelihood equation:
![]()
so that the parameters to estimate are only δi (item difficulties), and μ and σ² (population parameters). Such direct estimation method will give unbiased results for μ and σ². This is what ConQuest does. But most data analysts do not have ConQuest or other similar software that will enable them to do this direct estimation easily. Data analysts have available to them general statistical software such as SPSS and SAS. To allow the data analysts to compute the correct estimates of population parameters, plausible values are provided.
Recall that plausible values are random draws from each student's posterior distribution. The collection of posterior distributions for all students, put together, gives us an estimate of the population distribution, g(θ). Therefore, we can regard the collection of plausible values (over all students) as a sampling distribution from g(θ)). This is an important statement, and some results follow from this statement:
(1) Population characteristics (e.g., mean, variance, percentiles) can be constructed using plausible values.
(2) Supppose we generate 5 plausible values for each student, and form 5 sets of plausible values (set 1 contains the first plausible value for each student; set 2 contains the second plausible value for each student, etc.). Then each set is equally as good for estimating population characteristics, as each set forms a sampling distribution of g(θ). It follows that, even if we only use one plausible value per student to estimate population characteristics, we still have unbiased estimates, in contrast to using each student's EAP estimates (mean of plausible values for each student) and getting biased estimates. So the apparent paradox is that using one random draw (PV) from the posterior distribution is better than using the mean of the posterior, in terms of getting unbiased estimates.
Percent Below Cutpoint and Percentiles
The following example shows why point estimates are not the best for estimating percent in bands or percentiles. Suppose we have a 6-item test, so students' test scores range from 0 to 6. The Figure above shows the 7 (weighted) posterior distributions, corresponding to the 7 possible scores, and the corresponding EAP estimates (shown by the black vertical lines).
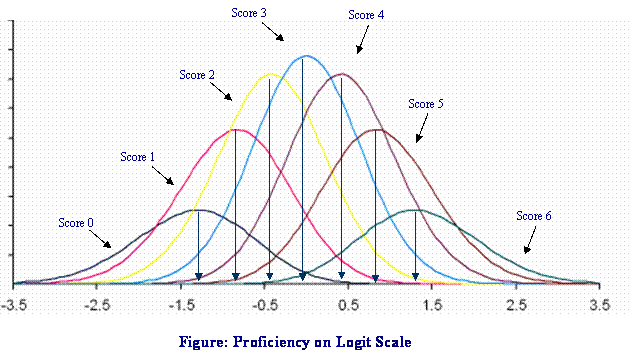
Suppose we are interested in the proportion of students below a cutpoint, say -1.0. If we use EAP estimates, then the proportion of people below -1.0 is the proportion of people obtaining a score of 0. In fact, for any cutpoint between EAP0 and EAP1, we obtain this same proportion because the (EAP) ability estimates are discrete, not continuous. In contrast, if we look at the area of the curves of the posterior distributions that is below -1.0, we see that this is a continuous function, and that this area contains contributions from all posterior distributions (corresponding to all scores).
As plausible values are random draws from the posterior distributions, the proportion of plausible values below a cutpoint gives us an estimate of the area of the posterior distributions below that cutpoint. By using plausible values, we are able to overcome the problems associated with the discrete nature of point estimates. Similarly, for percentiles, using plausible values will overcome the problem of having to interpolate between discrete ability estimates.
Some Simulation Results
Some simple simulation results are shown in the Table. A data file containing student responses was generated for a 20-item test with 300 students whose abilities were sampled from N(0,1). MLE, EAP and 5 PVs were computed for each student, and the sample mean and variance (across students) were computed for each of these estimates. This process was repeated 10 times (10 replications). Plausible values (and direct estimation) do a better job for estimating the population variance. That is, had we provided data analysts with students' MLE (or EAP) ability estimates, they would not be able to recover the variance (and other statistics such as percentiles) correctly.
| Averaged over 10 replications: | MLE | EAP | PV1 | PV2 | PV3 | PV4 | PV5 | Direct Estimate | Generating value |
| Ability mean | -0.05 | -0.05 | -0.05 | -0.04 | -0.06 | -0.04 | -0.05 | -0.05 | 0 |
| Ability variance | 1.45 | 0.78 | 1.01 | 0.99 | 1.01 | 1.00 | 1.01 | 1.00 | 1 |
Margaret Wu, Australian Council for Educational Research
Beaton, A. E. & Gonzalez, E. (1995). NAEP Primer. Chestnut Hill, MA, Boston College.
Journal of Educational Statistics (Summer 1992) Special Issue: NAEP.
Journal of Educational Measurement (Summer 1992) Special Issue: NAEP
Note: For ordinary estimates, plausible values are values from the error distribution of the estimate. If you have each person's estimate (measure, location) and its standard error, then plausible values are values selected at random from a normal distribution with its mean at the estimated measure and with standard deviation equal to the standard error. You can generate these with Excel or other statistical software.
Plausible Values, Wu M. … Rasch Measurement Transactions, 2004, 18:2 p. 976-978
| Forum | Rasch Measurement Forum to discuss any Rasch-related topic |
Go to Top of Page
Go to index of all Rasch Measurement Transactions
AERA members: Join the Rasch Measurement SIG and receive the printed version of RMT
Some back issues of RMT are available as bound volumes
Subscribe to Journal of Applied Measurement
Go to Institute for Objective Measurement Home Page. The Rasch Measurement SIG (AERA) thanks the Institute for Objective Measurement for inviting the publication of Rasch Measurement Transactions on the Institute's website, www.rasch.org.
| Coming Rasch-related Events | |
|---|---|
| May. 15 - June 12, 2026, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| June 19 - July 25, 2026, Fri.-Sat. | On-line workshop: Rasch Measurement - Further Topics (E. Smith, Winsteps), www.statistics.com |
| Aug. 31 - Sept 2 2026, Mon.-Wed. | In person: IMEKO TC1 Metrology Education and Training symposium, Klagenfurt, Austria www.photomet-edumet2026.com. Submissions by April 20 |
| Aug. 30 - Sept. 3, 2027, Mon.-Fri. | In Person: 2027 IMEKO World Congress (TC1, Tc7, TC13, TC18, TC26), Rimini, Italy imeko2027.org |
The URL of this page is www.rasch.org/rmt/rmt182c.htm
Website: www.rasch.org/rmt/contents.htm