
|
|
|
|
In Public Health, since many causes of disease, disability and death are preventable by behavior changes there is a strong reliance on designing and evaluating prevention-focused interventions. In designing these evaluations, researchers rely heavily on scales to assess complex variables including knowledge, attitudes and even behavior. Oftentimes, sensitive topics or behaviors are measured using these self-reported scales. Under Classical Test Theory (CTT) and using traditional statistical tests (e.g. t-tests on raw scores), evaluators assume equal interval properties of Likert-scales without ever systematically assessing whether the scales truly fit that assumption. The danger of this assumption is that if respondents are not using the rating scale categories in the hypothesized manner, results obtained from these analyses may be misleading or incorrect.
To illustrate this challenge, data from the longitudinal evaluation of the Americorps Program were used (CNS, 2004). Among the immediate hypothesized outcomes of the Americorps program are Awareness of Others/Diversity, impacted by both specific educational activities offered by the program and by the diversity of the Corps itself. The program hopes to improve participants' understanding of diverse cultures and backgrounds, and appreciation of the value of diverse people and opinions. The evaluation of the program included an 11-item Appreciation of Ethnic and Cultural Diversity Scale to assess the change in this latent variable.
While many interventions have a similar desired impact on appreciation of diversity and other potentially sensitive topics, measurement of this latent variable is fraught with challenges. For one, social norms impact respondent behavior on self-reported surveys, even those that employ validated scales. The extent to which these norms influence respondent behavior in self-administered surveys comprises Social Desirability Bias (e.g. Nederhof, 1985). Those interested in assessing variables highly susceptible to social norms should be particularly interested in detecting whether or not Social Desirability Bias is at work in their sample.
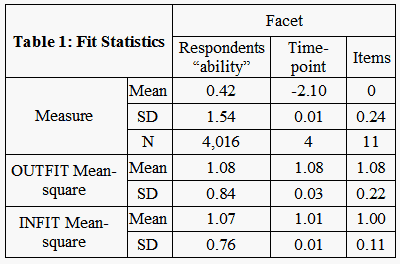
A partial credit FACETS model was run using the data from this evaluation (n=4,016). The model included three facets (respondents, items and time period/group) to account for the design of the original evaluation (which included a pre-test and post-test for both Americorps members and a comparison group). Overall fit for the model varied for each of the three facets (Table 1). While the mean OUTFIT mean-square for respondents was 1.08, close to its expected value of 1.0, the S.D. is somewhat larger than is the typically encountered for well-behaved data. 8% of the people had alarmingly large mean-square values over 2.0, forcing another 12% to have mean-square values less than 0.5. This misfit prompts an investigation into whether Social Desirability Bias may have influence these people's responses.
The items were asked using a five-point Likert-type scale. A FACETS model was used to estimate the mean "ability" (location on the latent variable) of those who responded in each category of each item's rating scale. If the mean abilities are disordered, this could indicate that our respondents did not treat the rating scale as strictly monotonic, resulting in empirically disordered categories. Consequently we could have reason to believe that Social Desirability Bias may have skewed the use of the rating scales.
Figure 1 shows three examples of the distribution of ability estimates for each of the five rating scale options. For example, for the second item the ability estimate that corresponds with Strongly Disagree is 0.83 logits, the ability estimate for Strongly Agree is 2.74 logits. Six of the eleven items show a similar disordering of the rating scale categories; in other words, for those items there is at least one point in the rating scale where the ability estimate that corresponds to the category goes down while the category goes up. This indicates that respondents chose a higher rating for those items than their actual ability; a sign that Social Desirability Bias is likely in play.
Using these methods to detect Social Desirability Bias may also provide opportunities to correct the analysis plan. Replacing rating scale category values (e.g. 1 for Strongly Disagree) with the estimated ability from the Rasch model, for example, will allow the analysis to take into account the disordered ratings of participants. This allows researchers to account for the impact of inaccurate self-assessment without altering the format of the scale itself.
Using CTT and t-tests on raw scores for these items assumes that Strongly Disagree is the lowest rating, but these results show that for some items Disagree represented the lowest rating. In the Americorps evaluation, participants from certain programs performed significantly worse on this variable at follow-up as compared to baseline. The evaluators concluded that program-related experiences, "may [have led] to short-term disillusion with the concept of working in diverse groups." This analysis, however, indicates that an alternate analysis approach that incorporates the ability estimates for each item's rating scale may provide a more accurate impact of the program that is less impacted by Social Desirability Bias.
Laura M. Lessard, MPH
Department of Behavioral Sciences and Health Education
Rollins School of Public Health
Emory University
Atlanta, Georgia
Nederhof, AJ. (1985). Methods of coping with social desirability bias: a review. European Journal of Social Psychology, 15: 263-280
Serving Country and Community: A Longitudinal Study of Service in Americorps. 2004, Corporation for National and Community Service (CNS), Office of Research and Policy Development: Washington, DC. Available at: http://www.americorps.org/pdf/06_1223_longstudy_report.pdf
Using a Partial-Credit Rasch Model to Detect Social Desirability Bias … L.M. Lessard, Rasch Measurement Transactions, 2008, 21:4 p. 1134-5
| Forum | Rasch Measurement Forum to discuss any Rasch-related topic |
Go to Top of Page
Go to index of all Rasch Measurement Transactions
AERA members: Join the Rasch Measurement SIG and receive the printed version of RMT
Some back issues of RMT are available as bound volumes
Subscribe to Journal of Applied Measurement
Go to Institute for Objective Measurement Home Page. The Rasch Measurement SIG (AERA) thanks the Institute for Objective Measurement for inviting the publication of Rasch Measurement Transactions on the Institute's website, www.rasch.org.
| Coming Rasch-related Events | |
|---|---|
| May. 15 - June 12, 2026, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| June 19 - July 25, 2026, Fri.-Sat. | On-line workshop: Rasch Measurement - Further Topics (E. Smith, Winsteps), www.statistics.com |
| Aug. 31 - Sept 2 2026, Mon.-Wed. | In person: IMEKO TC1 Metrology Education and Training symposium, Klagenfurt, Austria www.photomet-edumet2026.com. Submissions by April 20 |
| Aug. 30 - Sept. 3, 2027, Mon.-Fri. | In Person: 2027 IMEKO World Congress (TC1, Tc7, TC13, TC18, TC26), Rimini, Italy imeko2027.org |
The URL of this page is www.rasch.org/rmt/rmt214b.htm
Website: www.rasch.org/rmt/contents.htm