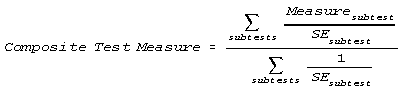|
Part-test vs. Whole-test Measures
S.E.(Composite measure) = 1 / √ ( Σ ( 1 / S.E.(Measure(subtest))² )) |
From a person's raw score on a whole-test, perhaps several hundred items long, that person's overall measure can be estimated. But the whole-test often contains several content-homogeneous subsets of items. From the person's raw score on each subset that person's measure on each subset can also estimated. How do the subset scores and measures compare with whole-test scores and measures?
For complete data, subset raw scores have the convenient numerical property that however the right answers are exchanged among subsets, the sum of part-test scores for each person still adds up to the same whole-test score. This forces the plot of mean part-test percent corrects against whole-test percent corrects into an identity line.
This simple additivity of subset raw scores, however, is somewhat illusory. It is an addition of instances, but not of meanings. To obtain meaning from raw scores, the raw scores must be converted into measures. But raw scores are necessarily non-linear (because they are bound by zero "right" and zero "wrong"). To convert them into linear measures, a linearizing transformation is required. This transformation must be ogival, as in [loge("rights"/"wrongs")].
Once the raw scores have been transformed non-linearly, the sum of parts can no longer correspond exactly to the whole. In fact, when mean measures for parts are plotted against the measure for the whole, the mean measures on part-tests are necessarily more extreme than the measures on the whole-test. Low part-test mean measures must be lower than their whole-test counterparts. High part-test mean measures are higher than their whole-test counterparts. Thus, when mean part-test measures are compared with whole-test measures, the mean part-test measures spread out more than their whole-test counterparts. In short, the variance of mean subtest measures is greater than the variance of whole test measures.
|
Part-test vs. Whole-test Measures
S.E.(Composite measure) = 1 / √ ( Σ ( 1 / S.E.(Measure(subtest))² )) |
Why does this happen? There are two causes:
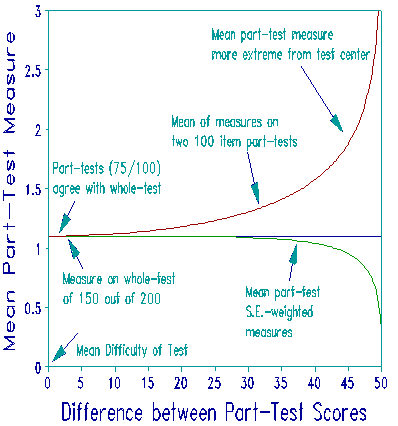
1. The effect of asymmetric non-linearity on score exchanges among part-tests. The Figure shows what happens when a person takes a whole-test with 200 dichotomous items, each of difficulty 0 logits and achieves a whole-test score of 150 correct. Look at the red line in Figure 1. The whole-test measure is loge(150/50) = 1.1 logits. But what happens when this performance is partitioned into two subtests of 100 items? When the score on both subtests is 75, then the mean subtest measure is loge(75/25) = 1.1 logits. But when one subset score is 90, then the other must be 60. Now the mean of the two subset measures becomes [loge(90/10) + loge(60/40)]/2 = [loge(9) + loge(1.5)]/2 = 1.3, i.e., higher! So, as the scores on the two subtests diverge, while maintaining the same total score, the mean subtest measure becomes higher. The mean measure becomes infinite when the score on one subtest is a perfect 100, and on the other test a middling 50.
The effect of asymmetric non-linearity on score exchanges results from the difference between any original raw (once only, specific, now a matter of history) data and its (inferential, general, to be useful in the future) meaning. Only when all part-test percent corrects are identical to their whole-test percent corrects, and all the part-test measures they imply are identical to the whole-test measures they imply, do mean part-test measures approach equality to whole-test measures.
As we investigate this, at first surprising but later persuasive, realization we discover that as the (surely to be expected) within person variation among part-test measures increases, the asymmetric effect of score exchanges on measures increases the variance of part-test measures and their means, making the distribution of part-test measures and means wider than the distribution of their corresponding whole-test measures. This happens no matter how carefully all item difficulties are anchored in the same well-constructed item bank and even when the part-tests exhaust the items in the whole test.
2. The increase in measurement error due to fewer items in the part-tests. Measurement error inflates measure variance. The observed sample measure variance on any test has two components: the "true", unobservably exact, variance of the sample and the error inevitably inherent in estimating each measure.
The measurement error component is dominated by the number of useful (targeted on, with difficulties near, the person measures) items. This factor is the usual reciprocal square root of replications. When the number of useful items decreases to a fourth, measurement error doubles. Thus, even for tests with identical targeting and content, the shorter the test, the wider the variance of the estimated measures.
A second factor contributing to "real" (as compared to theoretical, modelled) measurement error is response pattern misfit. The more improbable a person's response pattern, the more uncertain their measure. Misfit increases "real" measurement error beyond the modelled error specified by the stochastic model used to govern measure estimation. The more subsets comprise a whole-test, the more likely it is that local misfit will pile up unevenly in particular subsets and so perturb a person's measure for those subsets. Thus further increasing overall subset measure variance.
Scores vs. measures: The ogival shape of the linearizing transformation from scores to measures shows that one more "right" answer implies a greater increase in inferred measure at the extremes of a test (near 100 or zero percent) than in the middle (near 50 percent). So we must choose between scores and measures. But raw scores cannot remain our ultimate goal. What we need for the construction of knowledge is what raw scores imply about a person's typical, expected to recur behavior. When we take the step from data (raw experience) to inference (knowledge) by transforming an exactly observed raw score into an uncertain (qualified by model error and misfit) estimate of an inferred linear measure, the concrete one-for-one raw score exchanges between parts and wholes are left behind.
Implication: How, in everyday practice, are we to keep part-test measures quantitatively comparable to whole-test measures? First, we must construct all measures in the same frame of reference. Estimate item calibrations on the whole-test, then anchor all items at these calibrations when estimating part-test measures. Then, when the set of part-tests is complete and stable, one might consider simplifying scale management by formulating an empirically-based conversion between mean part-test and whole-test measures. For instance, look at the green line in Figure 1. Weighting part-test measures by their standard errors, Mean = (M1/SE1 + M2/SE2)/(1/SE1 + 1/SE2), brings them into closer conformity with the whole-test measures. This conversion will make things look more "right" to audiences who are still uncomfortable with the transition from concrete non-linear raw scores to the abstract linear measures they imply.
The utility of the mean of any set of parts, however, depends on the homogeneity of the part-measures. When the part-measures are statistically equivalent so that it is reasonable to think of them as replications on a common line of inquiry, then their mean is a reasonable summary and will be close to the whole-test measure. But then, if statistical equivalence among part-measures is so evident, what is the motivation for the partitions? In that case the most efficient and simplest interpretation of test performance is the single whole-test measure.
When, however, the differences among part-measures are significant enough (statistically or substantively) to become interesting, what then is the logic for either a part-measure mean or even a whole-test measure? Surely then one must deal with each part-test measure on its own, or else admit that the whole test measure is a compromise. The whole-test measure may be useful for coordinating representations of related, if now discovered to be usefully distinct, variables. But this "for-the-time-being" representationally convenient "common" metric loses its inferential significance as an unambiguous representation of a single variable.
Ben Wright
Combining Part-test vs whole-test measures. Wright BD. … Rasch Measurement Transactions, 1994, 8:3 p.376
| Forum | Rasch Measurement Forum to discuss any Rasch-related topic |
Go to Top of Page
Go to index of all Rasch Measurement Transactions
AERA members: Join the Rasch Measurement SIG and receive the printed version of RMT
Some back issues of RMT are available as bound volumes
Subscribe to Journal of Applied Measurement
Go to Institute for Objective Measurement Home Page. The Rasch Measurement SIG (AERA) thanks the Institute for Objective Measurement for inviting the publication of Rasch Measurement Transactions on the Institute's website, www.rasch.org.
| Coming Rasch-related Events | |
|---|---|
| Jan. 16 - Feb. 13, 2025, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| Apr. 8 - Apr. 11, 2026, Wed.-Sat. | National Council for Measurement in Education - Los Angeles, CA, ncme.org/events/2026-annual-meeting |
| Apr. 8 - Apr. 12, 2026, Wed.-Sun. | American Educational Research Association - Los Angeles, CA, www.aera.net/AERA2026 |
| May. 15 - June 12, 2026, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| June 19 - July 25, 2026, Fri.-Sat. | On-line workshop: Rasch Measurement - Further Topics (E. Smith, Winsteps), www.statistics.com |
The URL of this page is www.rasch.org/rmt/rmt83f.htm
Website: www.rasch.org/rmt/contents.htm