Item recalibration and stability. Lunz ME, Bergstrom BA. … 1995, 8:4 p.396
Immediate reporting of candidate abilities at the end of a computer-adaptive test (CAT) requires that abilities be estimated from banked item difficulties. These item difficulties are open to recalibration after a sample of candidates has been tested. For fairness and accuracy, it is important to project how different the ability estimates might have been, had they been based on recalibrated item difficulties.
In general, the impact of recalibration is small. For example,
when 2 or 3 percent of the items in the item bank change difficulty
by as much as 1.00 logit all in the same direction, this results,
on average, in an ability estimate change for a candidate who
responded to 100 items of:
2% x 1.0 logit = .02 logits ability change
3% x 1.0 logit = .03 logits ability change.
These changes are far less than the standard errors for candidates taking a CAT of 100 targeted items, because SEM for 100 items > (100*.25)**-1/2 = .2 logits. In practice, some items will recalibrate as more difficult, some as easier. Change in an ability estimate requires a change in the mean item difficulty of the items presented to the candidate.
As an empirical check, an investigation of estimation stability was conducted on CAT data collected in 1993 from 1,699 candidates responding to a pool of 792 items. A baseline group of 92 items and 549 candidates was identified. The criteria for inclusion were: 1) at least 100 baseline candidates answered each baseline item, and 2) at least 30 baseline items were administered to each baseline candidate.
Baseline ability measures and item calibrations were obtained using the entire baseline sample. The calibration for each item was based on the responses of baseline candidates to whom that item had been administered. Thus the number of relevant responses differed across items from 113 to 395. Then a series of independent Rasch analyses were performed for random samples of 30, 50, and 100 candidates from the baseline population of 549 candidates.
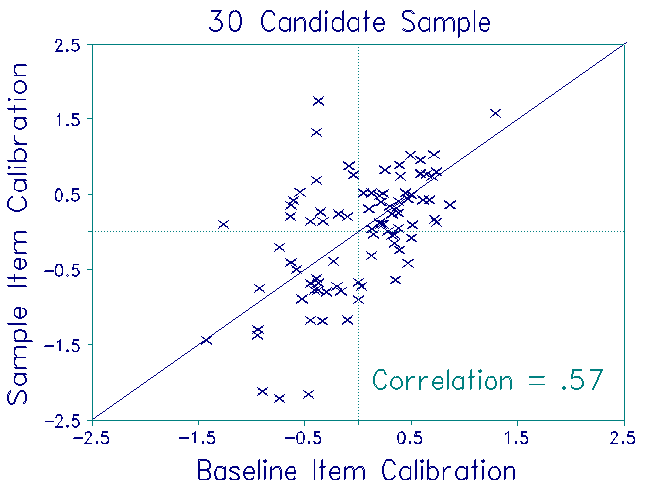
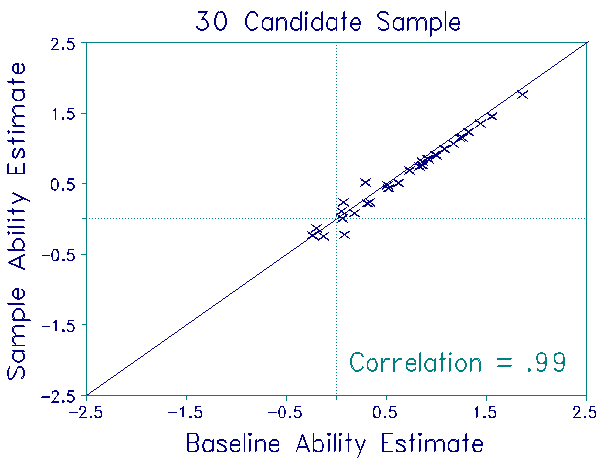
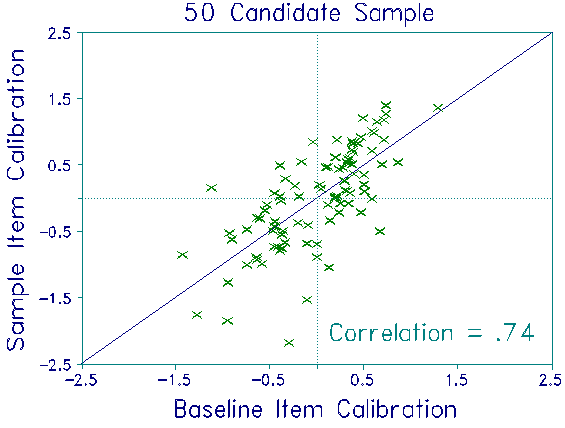
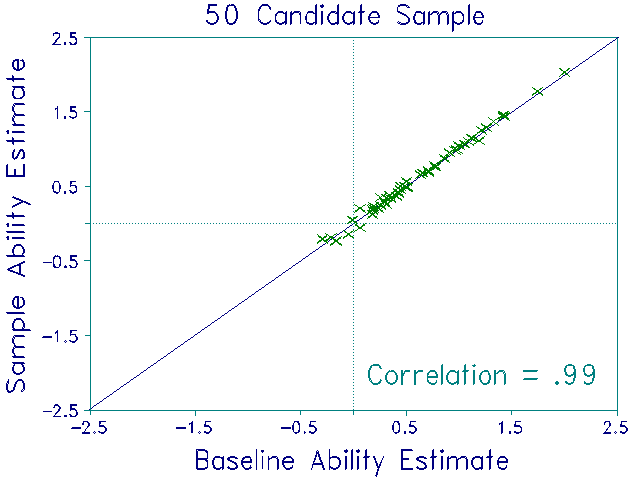
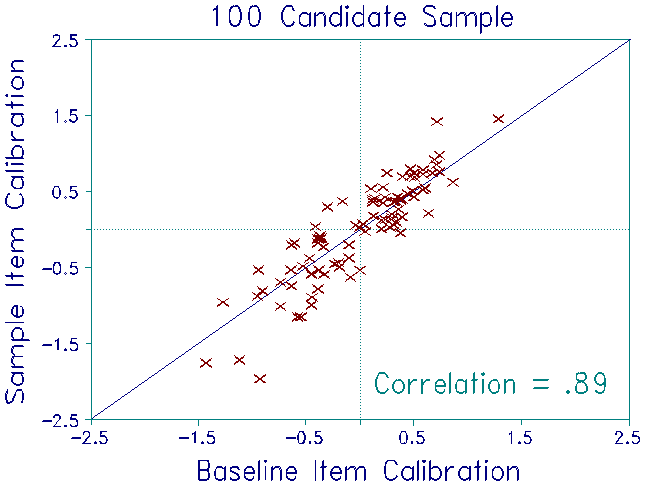
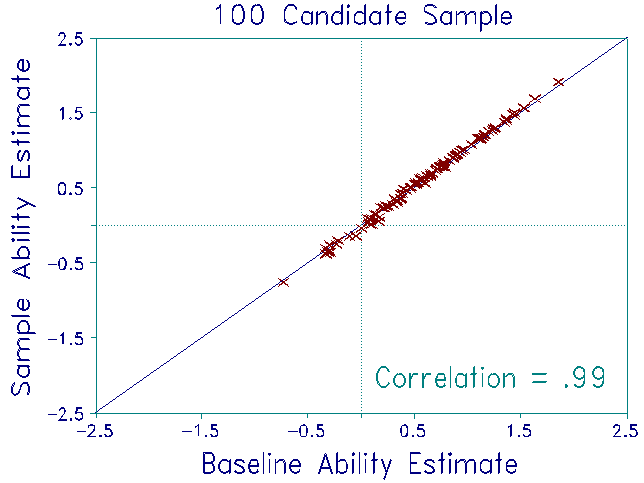
For each sample, item difficulties were estimated from whatever responses that sample's candidates had made. Thus, for the 30 candidate sample, 4 items had not been administered to any candidate in the sample. For the remaining 88 items, the number of responses to each item ranged from 8 to 24. For the 50 candidate sample, all 92 items were recalibrated from the responses of 9 to 40 candidates. For the 100 candidate sample, all 92 items were recalibrated from the responses of 16 to 73 candidates.
Candidate measures obtained from these three samples were compared to their baseline measures to investigate stability. The plots show the results. As expected, the item calibrations were quite unstable. Nevertheless, the ability estimates were stable, even under the most adverse conditions. No discrepancies exceeded the 0.3 logit S.E.of each ability measure. Though this finding is highly satisfactory, the impact of item recalibration on ability estimation in high-stakes situations can be reduced further. Keep the mean of the candidate ability estimates constant across recalibration, instead of setting the mean of the item difficulties equal to a constant (as was done here).
Item recalibration and stability. Lunz ME, Bergstrom BA. … Rasch Measurement Transactions, 1995, 8:4 p.396
| Forum | Rasch Measurement Forum to discuss any Rasch-related topic |
Go to Top of Page
Go to index of all Rasch Measurement Transactions
AERA members: Join the Rasch Measurement SIG and receive the printed version of RMT
Some back issues of RMT are available as bound volumes
Subscribe to Journal of Applied Measurement
Go to Institute for Objective Measurement Home Page. The Rasch Measurement SIG (AERA) thanks the Institute for Objective Measurement for inviting the publication of Rasch Measurement Transactions on the Institute's website, www.rasch.org.
| Coming Rasch-related Events | |
|---|---|
| May. 15 - June 12, 2026, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| June 19 - July 25, 2026, Fri.-Sat. | On-line workshop: Rasch Measurement - Further Topics (E. Smith, Winsteps), www.statistics.com |
| Aug. 31 - Sept 2 2026, Mon.-Wed. | In person: IMEKO TC1 Metrology Education and Training symposium, Klagenfurt, Austria www.photomet-edumet2026.com. Submissions by April 20 |
| Aug. 30 - Sept. 3, 2027, Mon.-Fri. | In Person: 2027 IMEKO World Congress (TC1, Tc7, TC13, TC18, TC26), Rimini, Italy imeko2027.org |
The URL of this page is www.rasch.org/rmt/rmt84g.htm
Website: www.rasch.org/rmt/contents.htm