Greetings
By measuring levels of examiner rating severity, differences
can be accounted for in the multi-facet analysis. Even though examiners differ in levels of
rating severity, they are able to distinguish among candidates' abilities.
Lidia Martinez
Manager, Test Development and Analysis
|
How Examiners of Different Severity Grade Candidates of
Different Ability
|
Overall differences in rating severity have been
shown for all oral performance examinations that require the intervention of
examiners. One of the assumptions of the
multi-facet model is that more able candidates will earn higher scores
regardless of the severity of the examiners or the difficulty of the task or
item. The purpose of this study is to show how examiners of different measured
severity grade candidates of different measured ability.
For this study, data were simulated based on oral
examination data and the multi-facet analysis was completed. The multi-facet
analysis program calculates a rating severity for each examiner based on all of
the ratings they give to all of the candidates they encounter during the
examination. The mean for examiner severity is 5.00 with a range of 2.99 to
9.34 scaled score points. Examiners were then divided into three groups based
on their severity, and labeled lenient (1 SD below the mean), moderate (within
1 SD of the mean), and severe (1 SD above
the mean).
The candidates were also divided into three
groups based on their measured ability with low ability (1 SD below the mean), moderate ability (within 1 SD of the mean), and high
ability (1 SD above the mean). Each graph shows each candidate ability group, with bars for the percent of ratings given
by lenient, moderate and severe examiners to that group. The rating scale is 1
= unsatisfactory (blue); 2 = marginal (green); 3 = satisfactory (tan), and 4 =
excellent (purple). The graphs are based on counts of the raw ratings given by
each examiner.
The first graph shows the high ability candidates (1SD above
the mean). As shown in the graph below,
severe examiners used the full range of ratings, gave fewer 4s than other
examiners, but many 3s (over 60%). Moderate
examiners gave primarily 3s and many 4s, while lenient examiners gave primarily
4s (over 60%) and many 3s. While the
patterns for all groups of examiners suggest able candidates, they are somewhat
different depending upon the overall expectations of the examiners.
|
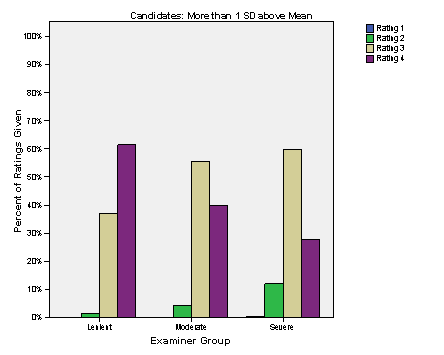
Figure 1.
The pattern for the least able candidates is quite different. Lenient and moderate
examiners used the entire rating scale. All examiners gave the lower ratings of
1 and 2, but lenient examiners gave them less frequently than moderate and
severe examiners. Lenient examiners gave 3s about 60% of the time, but 1s and
2s were given to some candidates. Moderate examiners gave primarily 2s and 3s.
Only 35% of the ratings given by severe examiners were 3s and there were no 4s.
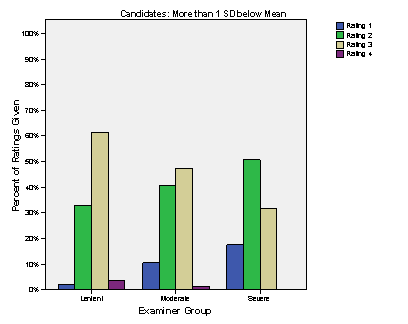
Figure 2.
For the moderate
group of candidates, examiners of all levels of severity used the full
range of the rating scale. Examiners tended
to give a high percentage of 3s, regardless of their severity. It is highly
probable that 3s are appropriate for moderate ability candidates. The lenient
examiners, as expected, gave the most 4s, but approximately 65% of their
ratings were 3s, which is similar to the moderate and severe examiners.
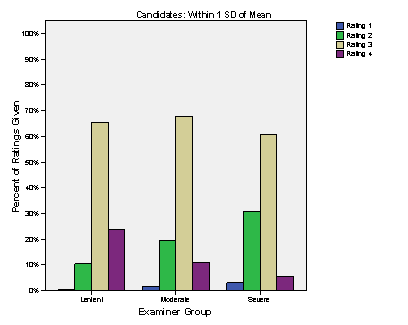
Figure 3.
It appears that all examiners, regardless of their level of
severity, can identify differences in candidate performance and give commensurate
ratings, even though those ratings may lean toward a pattern of severity,
moderation, or leniency. The lenient
examiners give higher ratings more frequently than other examiners, while the
more severe examiners tend to give lower ratings more frequently than other
examiners. Since the multi-facet analysis accounts for these differences in
examiner rating patterns, all candidates who are able to pass have a comparable
opportunity to pass regardless of the rating severity of the examiners they
happen to encounter.
|