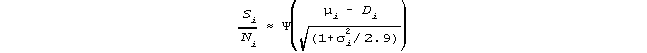For more than two facets, the {μi} and {σi} summarize the distribution of the combined measures of the other facets,
as encountered by item i, and similarly for the persons, tasks, judges, etc.
PROX for Complete Data
If data are complete, then μi and σi can be treated as constant across items, and μn and σn
constant across persons. This, with further simplifications, permits the non-iterative estimation equations derived by Cohen
(1979):
L = count of items
N = count of persons
Si is the raw score of successes on item i
Sn is the raw score of successes by person n
SDL = sample S.D. of item raw scores
SDN = sample S.D. of person raw scores
Item difficulties:
XL = item difficulty expansion factor = √ [(1+SDN/2.89)/(1-SDLSDN/8.35)]
Provisional difficulty of item i = - XL*ln[(Si)/(N-Si)]
Difficulty of item i = Provisional difficulty of item i - Average provisional difficulty of all items
with S.E. of item i = XL*√[N /(Si*(N-Si))]
Person abilities:
XN = person ability expansion factor = √ [(1+SDL/2.89)/(1-SDLSDN/8.35)]
Ability of person n = 0 + XN*ln[(Sn)/(L-Sn)]
with S.E. of person n = XN*√[L /(Sn*(L-Sn))]
PROX estimation equations for polytomous data will be derived in the next RMT.
John Michael Linacre
Camilli, G. 1994. Origin of the scaling constant d=1.7 in item response theory. Journal of Educational and Behavioral Statistics.
19(3) p.293-5.
Cohen, L. 1979. Approximate expressions for parameter estimates in the Rasch model. British Journal of Mathematical and
Statistical Psychology 32(1) 113-120.
PROX with missing data, or known item or person measures. Linacre JM. … Rasch Measurement Transactions, 1994, 8:3 p.378
| Rasch Books and Publications |
|---|
| Invariant Measurement: Using Rasch Models in the Social, Behavioral, and Health Sciences, 2nd Edn. George Engelhard, Jr. & Jue Wang |
Applying the Rasch Model (Winsteps, Facets) 4th Ed., Bond, Yan, Heene |
Advances in Rasch Analyses in the Human Sciences (Winsteps, Facets) 1st Ed., Boone, Staver |
Advances in Applications of Rasch Measurement in Science Education, X. Liu & W. J. Boone |
Rasch Analysis in the Human Sciences (Winsteps) Boone, Staver, Yale |
| Introduction to Many-Facet Rasch Measurement (Facets), Thomas Eckes |
Statistical Analyses for Language Testers (Facets), Rita Green |
Invariant Measurement with Raters and Rating Scales: Rasch Models for Rater-Mediated Assessments (Facets), George Engelhard, Jr. & Stefanie Wind |
Aplicação do Modelo de Rasch (Português), de Bond, Trevor G., Fox, Christine M |
Appliquer le modèle de Rasch: Défis et pistes de solution (Winsteps) E. Dionne, S. Béland |
| Exploring Rating Scale Functioning for Survey Research (R, Facets), Stefanie Wind |
Rasch Measurement: Applications, Khine |
Winsteps Tutorials - free
Facets Tutorials - free |
Many-Facet Rasch Measurement (Facets) - free, J.M. Linacre |
Fairness, Justice and Language Assessment (Winsteps, Facets), McNamara, Knoch, Fan |
| Other Rasch-Related Resources: Rasch Measurement YouTube Channel |
|---|
Rasch Measurement Transactions &
Rasch Measurement research papers - free |
An Introduction to the Rasch Model with Examples in R (eRm, etc.), Debelak, Strobl, Zeigenfuse |
Rasch Measurement Theory Analysis in R, Wind, Hua |
Applying the Rasch Model in Social Sciences Using R, Lamprianou |
El modelo métrico de Rasch:
Fundamentación, implementación e interpretación de la medida en ciencias sociales (Spanish Edition),
Manuel González-Montesinos M. |
| Rasch Models: Foundations, Recent Developments, and Applications, Fischer & Molenaar |
Probabilistic Models for Some Intelligence and Attainment Tests, Georg Rasch |
Rasch Models for Measurement, David Andrich |
Constructing Measures, Mark Wilson |
Best Test Design - free, Wright & Stone
Rating Scale Analysis - free, Wright & Masters |
| Virtual Standard Setting: Setting Cut Scores, Charalambos Kollias |
Diseño de Mejores Pruebas - free, Spanish Best Test Design |
A Course in Rasch Measurement Theory, Andrich, Marais |
Rasch Models in Health, Christensen, Kreiner, Mesba |
Multivariate and Mixture Distribution Rasch Models, von Davier, Carstensen |
Go to Top of Page
Go to index of all Rasch Measurement Transactions
AERA members: Join the Rasch Measurement SIG and receive the printed version of RMT
Some back issues of RMT are available as bound volumes
Subscribe to Journal of Applied Measurement
Go to Institute for Objective Measurement Home Page.
The Rasch Measurement SIG (AERA) thanks the Institute for Objective Measurement for inviting the publication of Rasch Measurement Transactions on the Institute's website, www.rasch.org.
| Coming Rasch-related Events |
|---|
| Jan. 16 - Feb. 13, 2025, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| Apr. 8 - Apr. 11, 2026, Wed.-Sat. | National Council for Measurement in Education - Los Angeles, CA, ncme.org/events/2026-annual-meeting |
| Apr. 8 - Apr. 12, 2026, Wed.-Sun. | American Educational Research Association - Los Angeles, CA, www.aera.net/AERA2026 |
| May. 15 - June 12, 2026, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| June 19 - July 25, 2026, Fri.-Sat. | On-line workshop: Rasch Measurement - Further Topics (E. Smith, Winsteps), www.statistics.com |
The URL of this page is
www.rasch.org/rmt/rmt83g.htm
Website: www.rasch.org/rmt/contents.htm