 |
 |
The placement of items along a variable defines the construct. For dichotomies, the location of items by their measures is unambiguous. Construct development proceeds immediately, see Chapter 5 of Best Test Design (Wright & Stone, 1979). For rating scales, item location is more nebulous. Chapter 7 of Rating Scale Analysis (Wright & Masters, 1982) points out how the construct is redefined when different standpoints on item difficulty are adopted. When an instrument contains multiple item types, the challenge is to build a clear, comprehensive, useful and defensible construct definition.
When data are collected on a rating scale, each category threshold, "step", has its own difficulty. This can be parameterized as Dij, the calibration of the jth step from category j-1 to category j for item i relative to the local origin of the measurement system. It can also be parameterized as Di + Fij, where Di is the calibration of the item relative to the local origin and Fij is the calibration of step j relative to Di. Mathematically, the two forms are equivalent. Conceptually they are different.
|
|
|
Consider the SF-36 Health Survey instrument. It contains not only dichotomies but also rating scales with 3, 5 and 6 categories. In discussing an item on a 6 category rating scale ("All of the time" to "None of the Time"), such as "Did you feel tired", we would overwhelm ourselves, as well as our audience, were we to describe all 5 of its step calibrations. Rather, we want to locate that item at one point along the variable, so that it can be compared with a "Yes/No" dichotomy, such as "Accomplished less than you would like".
The mathematically convenient item location is the one at which Fij=0 for the item. This is the point along the variable at which the highest and lowest categories for item i are equally probable, a type of mathematical "middle". The substantive meaning of this mathematical location, however, is usually obscure because it is an accident of how the categories have been labelled.
A more meaningful item location could be obtained by collapsing the rating scale into a dichotomy. The dichotomization of each item would be guided by one master criterion, such as "healthy vs. sick", with the actual pivot point for each item being decided by clinical judgement. Since the rating scale will not actually be collapsed into two categories, the pivot point may be in the middle of an ambivalent category, e.g., "Don't Know". Such uncertain categories, however, often contribute more noise than information and so are better treated as missing data.
Once the pivot point for each rating scale has been chosen by inspection of the category labels, then matching step calibrations can be imposed on the analysis. For instance, for the three category scale, "1. Yes, Limited A Lot", "2. Yes, Limited A Little", "3. No, Not Limited At All", the essential dichotomy between sickness and health contrasts categories 1 and 2 against category 3. The pivot point is between categories 2 and 3, where the step calibration is Fi3. This is the location relative to which the item difficulty is to be defined. Mathematically, Di + Fi3 Di, so, to obtain this pivot, set (anchor) Fi3=0.
The effects of anchoring steps are:
1) the data do not change unless explicitly recoded,
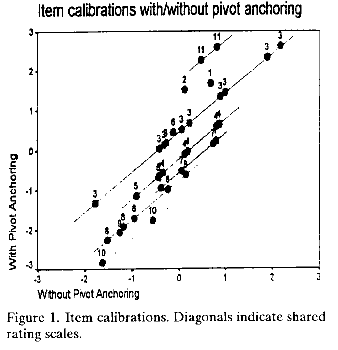
2) item difficulties do change (see Figure 1), redefining the construct. At bottom of Figure 1, the new "easiest item" is "13", previously it was the "3" at extreme left.
3) but items on the same rating scale retain their relative difficulties, so that these subsets retain their sub-construct definitions (diagonals in Figure 1),
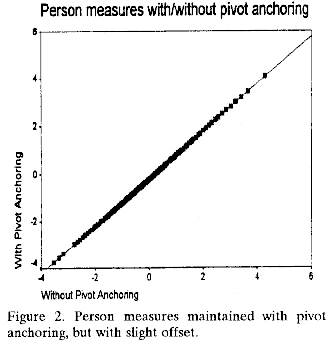
4) persons performances do not change nor do their relative measures (see Figure 2),
5) since the local origin of the measurement system is the mean item difficulty, all person measures may be changed, but by the same offsetting amount (diagonal offset in Figure 2).
Now each item difficulty is located according to a substantive criterion. Consequently, their ordering and relative location also have substantive meaning, aiding us in perceiving the criterion definition of the underlying construct.
Rita Bode
Rehabilitation Institute of Chicago
Pivot-Anchoring Items for Construct Definition. Bode R. … Rasch Measurement Transactions, 1997, 11:3 p. 576-7
| Forum | Rasch Measurement Forum to discuss any Rasch-related topic |
Go to Top of Page
Go to index of all Rasch Measurement Transactions
AERA members: Join the Rasch Measurement SIG and receive the printed version of RMT
Some back issues of RMT are available as bound volumes
Subscribe to Journal of Applied Measurement
Go to Institute for Objective Measurement Home Page. The Rasch Measurement SIG (AERA) thanks the Institute for Objective Measurement for inviting the publication of Rasch Measurement Transactions on the Institute's website, www.rasch.org.
| Coming Rasch-related Events | |
|---|---|
| May. 15 - June 12, 2026, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| June 19 - July 25, 2026, Fri.-Sat. | On-line workshop: Rasch Measurement - Further Topics (E. Smith, Winsteps), www.statistics.com |
| Aug. 31 - Sept 2 2026, Mon.-Wed. | In person: IMEKO TC1 Metrology Education and Training symposium, Klagenfurt, Austria www.photomet-edumet2026.com. Submissions by April 20 |
| Aug. 30 - Sept. 3, 2027, Mon.-Fri. | In Person: 2027 IMEKO World Congress (TC1, Tc7, TC13, TC18, TC26), Rimini, Italy imeko2027.org |
The URL of this page is www.rasch.org/rmt/rmt113e.htm
Website: www.rasch.org/rmt/contents.htm