Computer-adaptive testing gives wonderful flexibility. Certification tests can be administered at the candidate's convenience, as often as the candidate wants, until the candidate passes. But there is a book-keeping problem. How are we to keep track of all the items different candidates have seen in order to prevent asking a candidate the same question twice? Does it matter if we ask the same question twice?
On paper-and-pencil tests we don't want to ask questions from earlier test administrations on later administrations. This could enable candidates taking the test a second time to raise their raw scores, if they had taken the trouble to discover the answers to the test items they had seen.
On CAT tests, it is different. Everyone's raw scores are about the same. Failing candidates see a majority of easy items, i.e., those with difficulties below the pass-fail point. On these items, the failing candidate had a pre-set success rate (say 60%). Passing candidates have the same pre-set success rate, but on items that at least straddle the pass-fail point.
The concern is that a candidate might gain an unfair advantage, if that candidate saw items from the first CAT test again in the second CAT test. But if the candidate sees the same items twice, then that candidate is performing at the same level as in the first test administration, i.e., is failing! To pass the test, a candidate, who previously failed, must answer questions correctly that were harder than those previously administered. Answering previously administered questions correctly will improve that candidate's measure, but will only turn failure into success for a candidate who only just failed last time.
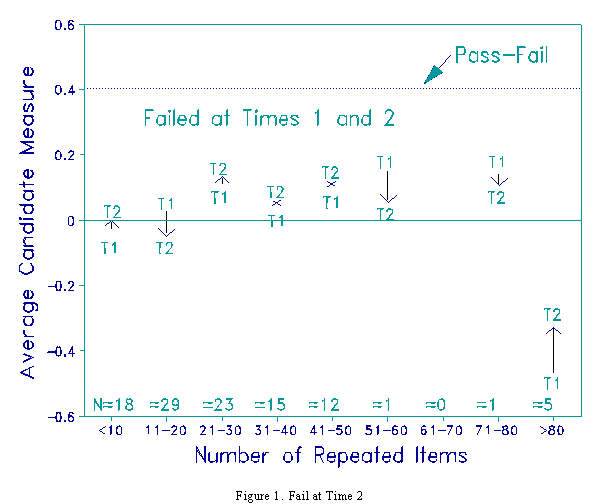
The Figures show what happened on a 90 item CAT test that was readministered to failing candidates some months later. The number of items common to the two tests for each candidate are shown. In Figure 1, the performance of the 104 candidates who failed both tests is shown. Their measures barely improve or even worsen. Apparently they had not made the effort even to study the items they saw the first time. Only the 5 very poorly performing candidates, who effectively took the same test over again, improve noticeably, but they are still a long way from passing.
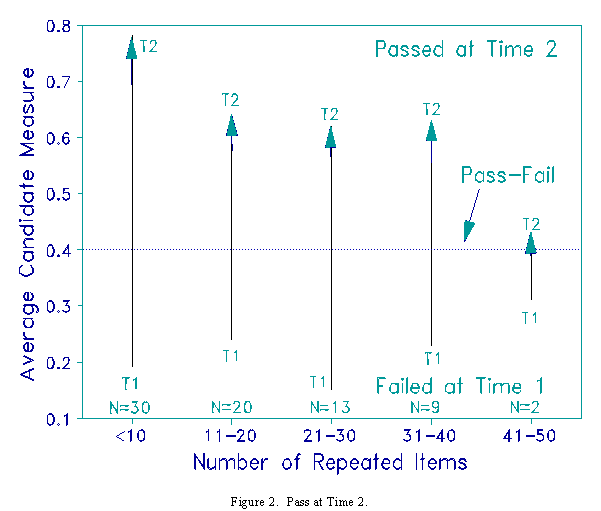
Figure 2 shows the 74 candidates who succeeded on their second attempt. Only those already close to the pass-fail line may have benefitted from seeing items for the second time.
Since the CAT success rate is set at 60% and candidates are administered 90 items, these candidates failed about 36 items the first time. There is no advantage to being readministered items passed that first time. The credit for success both times is identical. The advantage would be in changing wrong answers to right answers. On average for all 178 candidates, they changed 4 wrong answers to right answers, but also 3 right answers to wrong!
Imagine that, during the second CAT test of 90 items, a candidate, whose ability was unchanged, happened to be readministered the 36 items answered wrongly the first time. Answering all these items correctly would raise the candidate's measure by about 0.5 logits. This could explain why the 2 candidates passed who received 41-50 repeat items. In practice, one would check whether this was the case before making the final pass-fail decision. In order to verify the accuracy of the candidate's measure, an ability estimate would be made based solely on the responses to non-repeated items. If this estimate is above the pass-fail criterion, the candidate is a genuine pass.
Mary Lunz, Institute for Objective Measurement
Tom O'Neill, American Society of Clinical Pathologists
CAT: Taking items twice? Lunz M.E., O'Neill T.R. … Rasch Measurement Transactions, 1998, 12:3 p. 656-7.
| Forum | Rasch Measurement Forum to discuss any Rasch-related topic |
Go to Top of Page
Go to index of all Rasch Measurement Transactions
AERA members: Join the Rasch Measurement SIG and receive the printed version of RMT
Some back issues of RMT are available as bound volumes
Subscribe to Journal of Applied Measurement
Go to Institute for Objective Measurement Home Page. The Rasch Measurement SIG (AERA) thanks the Institute for Objective Measurement for inviting the publication of Rasch Measurement Transactions on the Institute's website, www.rasch.org.
| Coming Rasch-related Events | |
|---|---|
| May. 15 - June 12, 2026, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| June 19 - July 25, 2026, Fri.-Sat. | On-line workshop: Rasch Measurement - Further Topics (E. Smith, Winsteps), www.statistics.com |
| Aug. 31 - Sept 2 2026, Mon.-Wed. | In person: IMEKO TC1 Metrology Education and Training symposium, Klagenfurt, Austria www.photomet-edumet2026.com. Submissions by April 20 |
| Aug. 30 - Sept. 3, 2027, Mon.-Fri. | In Person: 2027 IMEKO World Congress (TC1, Tc7, TC13, TC18, TC26), Rimini, Italy imeko2027.org |
The URL of this page is www.rasch.org/rmt/rmt123m.htm
Website: www.rasch.org/rmt/contents.htm