is the striking title of a recent book edited by Susan E. Embretson and Scott L. Hershberger (Mahway, NJ: Lawrence Erlbaum, 1999). There are 11 informative chapters packed with real-life Rasch-related applications. Solid theory is presented, graphically and through practical implications, rarely as bald algebra.
But how I wish my copy had a global replace feature! In almost every instance where the letters IRT appear, one must replace them with Rasch. For instance, "IRT item parameters are not biased by the population ability distribution" (p. 2). As has been demonstrated repeatedly (e.g., RMT 6:2, 217), this is a characteristic of only the Rasch model and not at all a general characteristic of IRT models.
So what are Susan Embretson's New Rules?
Rule 1: The Standard Error of Measurement
Old Rule 1. The standard error of measurement applies to all scores in a particular population.
New Rule 1. The standard error of persons differs between persons with different response patterns, but generalizes across [similar] populations.
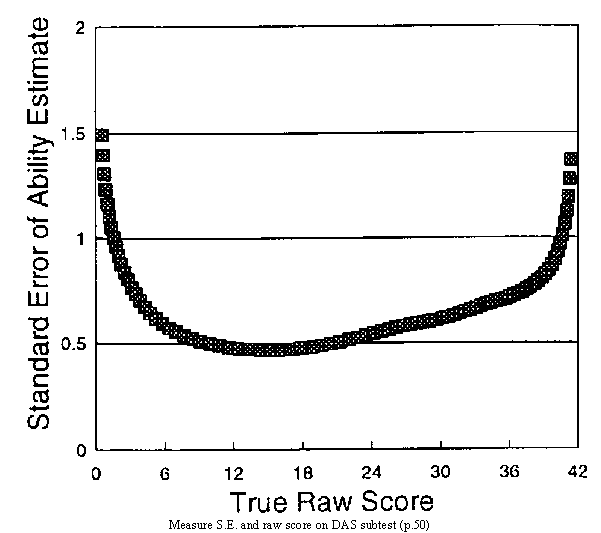
Of course, theorists in the classical tradition know that different raw scores have different standard errors. Nevertheless, "if the score distribution approaches normality, and if obtained scores do not extend over the entire possible range, the standard error of measurement is probably uniform at all score levels" (Guilford, 1965 p. 445). Indeed, a plot on p. 50 (reprinted below) of New Rules confirms that S.E.s can be reasonably uniform across most of the range of raw scores. Also, since the easiest way to compute raw score standard errors is from reliability coefficients, most classical analysts never go beyond computing one global standard error estimate.
So what are the real implications of Rule 1? As New Rules points out, standard errors of measures increase to infinity as scores become extreme. Standard errors of raw scores decrease to zero, misleading the analyst into believing that zero and perfect scores imply exact knowledge of the location of examinees on the latent variable. Further, examinee measures (as opposed to raw scores) are each identified with their own standard error, irrespective of who, if any one, takes the same test. Decisions can be made on an individual rather than group basis.
Rule 2. Test Length and Reliability
Old Rule 2. Longer tests are more reliable than shorter tests.
New Rule 2. Shorter tests can be more reliable than longer tests.
No, as New Rules clarifies, the Spearman-Brown prophecy formula is not revoked. Provided everything stays the same, a longer test of the same sort of items is more reliable than a shorter test. But a longer test is not necessarily more reliable than a different, shorter test. Of course, classicists know this, "Internal-consistency reliability is the greatest when ... the variance of items is greatest. This is when the proportion passing an item is .50" (Guilford p. 464). But classicists couldn't do much with this knowledge, because everyone had to take the same test, and test content was fixed. Now there are item banks and computer-adaptive testing. For instance, a 20-item on-target test can measure more reliably than a 30-item test on which an examinee achieves 80% success, and that can be more reliable than a 50-item test with 90% success.
Rule 3. Interchangeable Test Forms
Old Rule 3. Comparing test scores across multiple forms depends on test parallelism or test equating.
New Rule 3. Comparing test scores across multiple forms is optimal when test difficulty levels vary between persons.
What? Is test equating abolished? No - the emphasis has shifted. The goal is no longer to match the new test to the old test, it is to match the new test to the new person. Item banks are the key. (How did a reference to Wright & Bell, 1984, escape the editors of New Rules?) With pre-calibrated items, parallel forms and equi-percentile equating are obsolete.
Rule 4. Unbiased Assessment of Item Properties.
Old Rule 4. Unbiased assessment of item properties depends on representative samples from the target population.
New Rule 4. Unbiased estimates of item properties may be obtained from unrepresentative samples.
What does bias mean? It means incorrect decisions due to poor test-to-sample targeting. What does representative mean? It means the sample ability distribution matches that of the population. Classical item selection criteria, such as p-value for item difficulty and discrimination index for item quality, are optimal for items targeted on the sample. If the distribution of the pilot sample does not match the distribution of the test population, replacing "bad" items could make the test worse, not better! But even under the best of circumstances, classical analysis is biased against those items which best measure the high and low performers.
Now items are assessed on their own merits. Each item is chosen for the role it plays in constructing measures for those examinees on whom it is targeted, without giving misleading information about others who might happen to encounter it. Each item is designed to be as similar to the other items as possible, in the sense of measuring the same construct and eliciting the same type of behavior from respondents. Each item is also designed to be as different from the other items as possible, in the sense of obtaining its own share of brand-new information about the performance level of respondents.
These four rules are those identified by Susan Embretson (p. 11-14). But New Rules reaches much farther. For instance, a new rule is that raw scores have substantive implications (p. 247-8). Another new rule is that the hierarchy of item difficulty reflects a meaningful, valid construct (p. 248-9). An additional new rule is that examinee response patterns have diagnostic meaning (p. 250-252). And still more rules emerge in chapter after chapter.
John Michael Linacre
Guilford JP. 1965. Fundamental Statistics in Psychology and Education. New York: McGraw-Hill.
Wright BD, Bell SR. 1984. Item banks: what, why, how? Journal of Educational Measurement, 21:4, 331-345.
The New Rules for Measurement Embretson S.E. commented by Linacre, J.M. … Rasch Measurement Transactions, 1999, 13:2 p. 692
| Forum | Rasch Measurement Forum to discuss any Rasch-related topic |
Go to Top of Page
Go to index of all Rasch Measurement Transactions
AERA members: Join the Rasch Measurement SIG and receive the printed version of RMT
Some back issues of RMT are available as bound volumes
Subscribe to Journal of Applied Measurement
Go to Institute for Objective Measurement Home Page. The Rasch Measurement SIG (AERA) thanks the Institute for Objective Measurement for inviting the publication of Rasch Measurement Transactions on the Institute's website, www.rasch.org.
| Coming Rasch-related Events | |
|---|---|
| May. 15 - June 12, 2026, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| June 19 - July 25, 2026, Fri.-Sat. | On-line workshop: Rasch Measurement - Further Topics (E. Smith, Winsteps), www.statistics.com |
| Aug. 31 - Sept 2 2026, Mon.-Wed. | In person: IMEKO TC1 Metrology Education and Training symposium, Klagenfurt, Austria www.photomet-edumet2026.com. Submissions by April 20 |
| Aug. 30 - Sept. 3, 2027, Mon.-Fri. | In Person: 2027 IMEKO World Congress (TC1, Tc7, TC13, TC18, TC26), Rimini, Italy imeko2027.org |
The URL of this page is www.rasch.org/rmt/rmt132e.htm
Website: www.rasch.org/rmt/contents.htm