
The detection of differences in item performance (DIF, Differential Item Functioning) for different groups of examinees is important if tests equivalent for these groups are to be designed and maintained.
| ETS DIF Category | with DIF Size (Logits) and DIF Statistical Significance | |
|---|---|---|
| C = moderate to large | |DIF| ≥ 0.64 logits | prob( |DIF| ≤ 0.43 logits ) < .05 approximately: |DIF| > 0.43 logits + 2 * DIF S.E. |
| B = slight to moderate | |DIF| ≥ 0.43 logits | prob( |DIF| = 0 logits ) < .05 approximately: |DIF| > 2 * DIF S.E. |
| A = negligible | - | - |
| C-, B- = DIF against focal group; C+, B+ = DIF against reference group | ||
| Note: ETS (Educational Testing Service) use Delta units. 1 logit = 2.35 Delta δ units. 1 Delta δ unit = 0.426 logits. | ||
| Zwick, R., Thayer, D.T., Lewis, C. (1999) An Empirical Bayes Approach to Mantel-Haenszel DIF Analysis. Journal of Educational Measurement, 36, 1, 1-28 | ||
Differential Item Performance by Mantel-Haenszel
The Mantel-Haenszel (MH) procedure (Mantel & Haenszel, 1959) is sometimes claimed to be the best method for detecting this kind of item bias (Holland & Thayer, 1986). The first step of the MH procedure is to identify two contrasting examinee groups. These are the reference group, R, chosen to provide the standard performance on the item of interest, and the focal group, F, whose differential performance, if any, is to be detected and measured.
The MH procedure requires that these groups be matched according to a relevant stratification. Since there are seldom any clear external factors by which to match the strata of these groups, implied levels of ability are used. The ability range of the groups is divided into K (usually three to five) score intervals, and these intervals are used to match samples from each group. A 2x2 contingency table for each of these K ability intervals is constructed from the responses to the suspect item by the examinees of each group. The table of responses made by the two sample groups in the jth ability interval has the form shown in the Table.
| Response to Suspect Item | |||
|---|---|---|---|
| Group j | Right (1) | Wrong (0) | Total |
| Reference group | Aj (PRj1 ) | Bj (PRj0 ) | |
| Focal group | Cj (PFj1 ) | Dj (PFj0 ) | |
| Total | Tj | ||
The MH procedure is based on estimating the probability of a member of the reference group in interval j getting the item right, PRj1, or getting it wrong, PRj0, and similarly for a member of the focal group, PFj1 and PFj0. Two statistics are derived: an estimate of the significance of the difference, and an estimate of the size of the difference. Often only the significance of the difference is reported. But, since for large samples, meaninglessly small differences can be reported as significant, the discussion here will be concerned with the estimation of the size of the difference.
The MH estimate, α, of the difference in performance on an item between the two groups across all intervals is
|
|
in which α has the range 0 to infinity, and a "no difference" null value of 1. A popular transformation of this statistic to create a symmetric scale with a null value of zero is
δ = - (4/1.7) ln(α), so that Delta = -2.35 * logit
however, δ = ln(α) is just as useful.
Holland & Thayer (1986) do not offer a useful standard error for this estimate, but subsequent work has suggested some possibilities.
Estimating the MH Estimator
The application of the MH procedure requires an understanding of what these statistics estimate. The α estimator estimates a parameter which fulfills

|
Since the number of ability intervals, K, is arbitrary, the parameter, α, must be kept independent of the number of levels chosen, and constant across those intervals, if it is to have meaning beyond the arbitrary stratification scheme chosen by the analyst. This condition must hold even for strata defined to contain only examinees with the same raw score, k, on the test. Thus consider the value of αk estimated based on this interval,
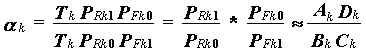
|
This yields the log-odds estimation equation,
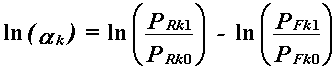
|
which has exactly the same mathematical features as the Rasch model, implying that MH will work successfully only on data that usefully fit the Rasch model.
The general MH relationship must also hold, in just the same way, for a score interval adjacent to j, say, h,
|
|
Both αk and αh estimate the same value, α. But if k and h are combined into the same interval, they must yield a third, equally valid, estimate of the same value α, namely, αkh. Then
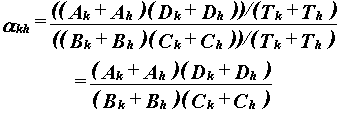
|
This cannot, in general, yield the same estimate of α as αk or αh.
If Ak=4, Bk=2, Ck=1 and Dk=2, then αk=4. If Ah=16, Bh=4, Ch=1 and Dh=1, then αh=4, as well.
But Ak+Ah=20, Bk+Bh=6, Ck+Ch=2, Dk+Dh=3, and so αkh=5, which differs from αk = αh = 4.
The estimate of α depends in an arbitrary way on the manner in which the intervals happen to be formed by the analyst.
Parameterizing Differential Item Performance
The Rasch model specifies that each examinee has an ability, B, and each item a difficulty, D. If there is differential item performance, the item difficulty for the reference group, DR, will be different from the item difficulty for the focal group, DF.
Responses to items on the test, other than the suspect items, can be used to determine ability estimates for the members of both groups, and also item difficulties for all non-suspect items.
Rasch analysis yields an ability estimate, B, for each examinee in each score-group on a common interval scale. By examining performance on each suspect item, Rasch estimates can be obtained for parameters which satisfy, for each member of the reference group:
B - DR = ln(PR1 / PR0)
and for each member of the focal group:
B - DF = ln(PF1 / PF0)
Since Rasch objectivity places all examinees with the same raw score on the same set of items at the same ability, we can compare the performance on the suspect item of equal scoring examinees in the two groups. This gives, for a score of k,
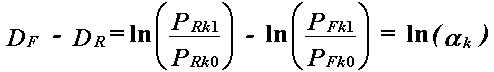
|
which is identical to the formulation derived for the ln(αk) MH parameter. Thus the Rasch and MH approaches are both based on the relative odds of success of the two groups on the suspect item. The difference between the two methods is only in how this relationship is estimated and informed.
A Rasch Approach to Item Bias Detection
The item difficulty for the suspect item for the matched reference and focal groups can be estimated by the non-iterative normal approximation algorithm (PROX) (Wright and Stone, 1979 Chap. 2). Whenever a sample of person abilities can be represented by a normal distribution for the reference group, they can be subsumed into one group, j, and
DR = MR + XR ln(Bj / Aj)
where DR is the estimated difficulty of the suspect item for the reference group, MR is the mean ability of the reference group, and XR is a correction factor for the distribution of reference group abilities, given by sqrt(1 + VR/2.9), with VR being the ability variance of the reference group.
Similarly, for a sample of the focal group,
DF = MF + XF ln(Dj / Cj)
Thus PROX provides estimates of DR and DF and so of the item bias, DF - DR. The model standard error of this bias is
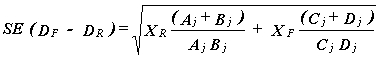
|
A simple test of the significance of the bias is
z = (DF - DR) / SE(DF - DR)
Thus whenever the ability distributions of the reference and focal groups are approximately normal, PROX can be used for estimating and testing the magnitude of item bias.
When data fit this Rasch model, the estimates DF and DR become independent of the ability composition of the reference group and focal group examinees. Consequently the comparison of DF and DR does not require any stratification or any matching of ability levels. Further, the estimates DF and DR can be calculated from all, or any convenient subset, of the reference and focal groups without any arbitrary stratification or matching. The item bias for or against the focal group is the difference between these estimates. The standard errors for DF and DR are well-defined and thus provide a standard error for their difference, the bias. These standard errors depend on the numbers of examinees and their ability distributions, but are independent of the size of the difference between DF and DR.
Comparison of MH and Rasch Approaches
The fundamental requirement of the MH procedure is that the probabilities of success for the reference and focal groups bear the same relationship across all groupings. This uniformity of relationship is required to calculate a stable estimate of the MH α statistic. But this calculation also requires the imposition of an arbitrary segmentation and matching scheme on the groups to be compared, and this arbitrary selection of interval boundaries affects the magnitude of the MH α estimate.
Rasch analysis expects the same data conditions that the MH procedure implies and requires. But, by utilizing all the relevant information from every response by reference and focal groups, Rasch analysis is able to provide a stable equivalent to the MH ln(α) statistic with an easily estimable standard error.
The Mantel-Haenszel procedure is an attempt to determine indirectly what routine Rasch analysis provides directly. The MH procedure involves theoretical uncertainties and is affected by arbitrary decisions by the analyst who uses it. If one is not prepared to accept the validity of the data under examination for Rasch analysis, then the MH procedure's implicit assumption of the stability of the relationship of the odds-ratios across ability groups will not be satisfied either. If one is prepared to accept the Rasch conditions, however, the PROX algorithm yields simpler and better defined statistics.
John M. Linacre and Benjamin D. Wright
Holland, P.W., & Thayer, D.T. (1986) Differential item performance and the Mantel-Haenszel procedure (Technical Report No. 86-69). Princeton, NJ: Educational Testing Service.
Mantel, N., & Haenszel, W. (1959) Statistical aspects of the analysis of data from retrospective studies of disease. Journal of the National Cancer Institute, 22, 719-748.
Wright, B.D., & Stone, M.H. (1979) Best Test Design. Chicago, IL: MESA Press.
Mantel-Haenszel DIF and PROX are Equivalent! Linacre J.M. & Wright B.D. … Rasch Measurement Transactions, 1989, 3:2 p.52-53
| Forum | Rasch Measurement Forum to discuss any Rasch-related topic |
Go to Top of Page
Go to index of all Rasch Measurement Transactions
AERA members: Join the Rasch Measurement SIG and receive the printed version of RMT
Some back issues of RMT are available as bound volumes
Subscribe to Journal of Applied Measurement
Go to Institute for Objective Measurement Home Page. The Rasch Measurement SIG (AERA) thanks the Institute for Objective Measurement for inviting the publication of Rasch Measurement Transactions on the Institute's website, www.rasch.org.
| Coming Rasch-related Events | |
|---|---|
| May. 15 - June 12, 2026, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| June 19 - July 25, 2026, Fri.-Sat. | On-line workshop: Rasch Measurement - Further Topics (E. Smith, Winsteps), www.statistics.com |
| Aug. 31 - Sept 2 2026, Mon.-Wed. | In person: IMEKO TC1 Metrology Education and Training symposium, Klagenfurt, Austria www.photomet-edumet2026.com. Submissions by April 20 |
| Aug. 30 - Sept. 3, 2027, Mon.-Fri. | In Person: 2027 IMEKO World Congress (TC1, Tc7, TC13, TC18, TC26), Rimini, Italy imeko2027.org |
The URL of this page is www.rasch.org/rmt/rmt32a.htm
Website: www.rasch.org/rmt/contents.htm