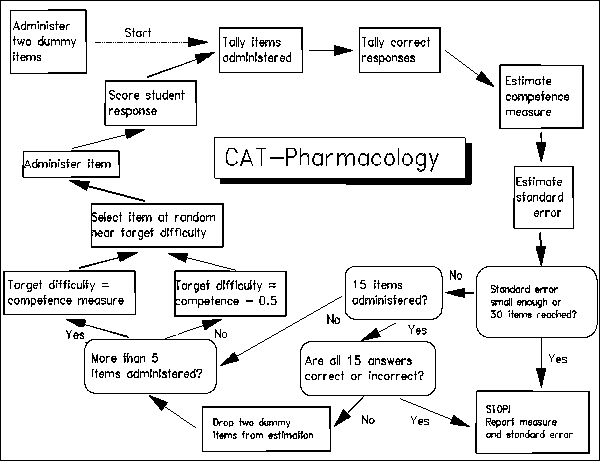
CAT-Pharmacology is a computer-adaptive test designed to measure the competency of nursing students in three areas: calculations, principles of drug administration and effects of medications. It modernizes our testing procedures by replacing conventional classical test theory (CTT) with Rasch measurement, and clumsy paper-and-pencil administration with stream-lined CAT.
For each area, an item bank has been constructed using text and calibrations obtained from paper-and-pencil tests administered to 4496 examinees.
To begin CAT, a Bayesian ability estimate is provided by awarding each student one success and one failure on two dummy items at the mean difficulty, D0, of the sub-test item bank. Thus each student's initial ability estimate is the mean item difficulty.
The first item a student sees is selected at random from those near 0.5 logits less than the initial estimated ability. This yields a putative 62% chance of success, thus providing the student, who may not be familiar with CAT, extra opportunity for success within the CAT framework. Randomizing item selection improves test security by preventing students from experiencing similar tests. Randomization also equalizes bank item use.
After the student responds to the first item, a revised competency measure and standard error are estimated. Again, an item is chosen from those near 0.5 logits easier than the estimated competency. After the student responds, the competency measure is again revised and a further item selected and administered. This process continues.
After each m responses have been scored with Rm successes, a revised competency measure, Bm+1, is obtained from the previous competency estimate, Bm, by:
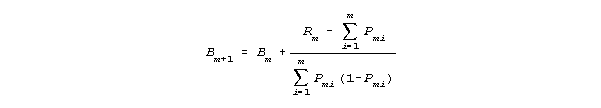
The logit standard error of this estimate, SEm+1, is
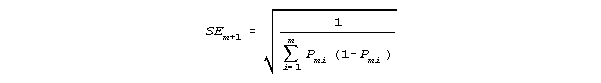
Pmi is the modelled probability of success of a student of ability Bm on the ith administered item of difficulty Di,
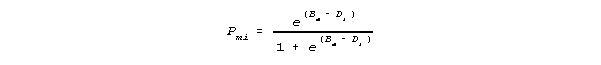
The initial two dummy items (one success and one failure on items of difficulty D0) can be included in the summations. This will reduce the size of the change in the ability estimate, preventing early nervousness or luck from distorting the test.
Beginning with the sixth item, the difficulty of items is targeted roughly directly at the person competency, rather than 0.5 logits below. This optimal targeting theoretically provides the same measurement precision with 6% fewer test items - but always allow some randomness in item selection in order to prevent "tracking" through the item bank.
If, after 15 responses, the student has succeeded (or failed) on every administered item, testing ceases. The student is awarded a maximum (or minimum) measure. Otherwise, the two dummy items are dropped from the estimation process.
There are two stopping rules. All tests cease when 30 items have been administered. Then the measures have standard errors of 0.4 logits. Some tests may end sooner, because experience with the paper-and-pencil test indicates that less precision is acceptable when competency measures are far from mean item bank difficulty. After item administration has stopped, the competency estimate is improved by several more iterations of the estimation algorithm to obtain a stable final measure. This measure and its standard error are reported for decision making.
Perry N. Halkitis
Chief Psychometrician
NLN Test Service
350 Hudson Street, New York NY 10014-4504
Halkitis, P.N. (1993) Computer-adaptive testing algorithm. Rasch Measurement Transactions 6:4 p. 254-5.
CAT algorithm. Halkitis PN. … Rasch Measurement Transactions, 1993, 6:4 p.254-5
| Forum | Rasch Measurement Forum to discuss any Rasch-related topic |
Go to Top of Page
Go to index of all Rasch Measurement Transactions
AERA members: Join the Rasch Measurement SIG and receive the printed version of RMT
Some back issues of RMT are available as bound volumes
Subscribe to Journal of Applied Measurement
Go to Institute for Objective Measurement Home Page. The Rasch Measurement SIG (AERA) thanks the Institute for Objective Measurement for inviting the publication of Rasch Measurement Transactions on the Institute's website, www.rasch.org.
| Coming Rasch-related Events | |
|---|---|
| May. 15 - June 12, 2026, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| June 19 - July 25, 2026, Fri.-Sat. | On-line workshop: Rasch Measurement - Further Topics (E. Smith, Winsteps), www.statistics.com |
| Aug. 31 - Sept 2 2026, Mon.-Wed. | In person: IMEKO TC1 Metrology Education and Training symposium, Klagenfurt, Austria www.photomet-edumet2026.com. Submissions by April 20 |
| Aug. 30 - Sept. 3, 2027, Mon.-Fri. | In Person: 2027 IMEKO World Congress (TC1, Tc7, TC13, TC18, TC26), Rimini, Italy imeko2027.org |
The URL of this page is www.rasch.org/rmt/rmt64cat.htm
Website: www.rasch.org/rmt/contents.htm