What can be reported to a CAT examinee? Raw scores are meaningless. Percentiles provide no substantive guidance on strengths and weaknesses. Even measures have little value without a context.
Instructionally useful diagnostic information can be given, however, by using a variation of KIDMAP output (Wright, Mead, and Ludlow, 1980). This is implemented in the IPARM program (Smith, 1991). This program performs item and person analysis at a higher level of detail than calibration programs. The "IPARMM" option creates detailed maps of examinee performance for fixed length or computer adaptive tests.
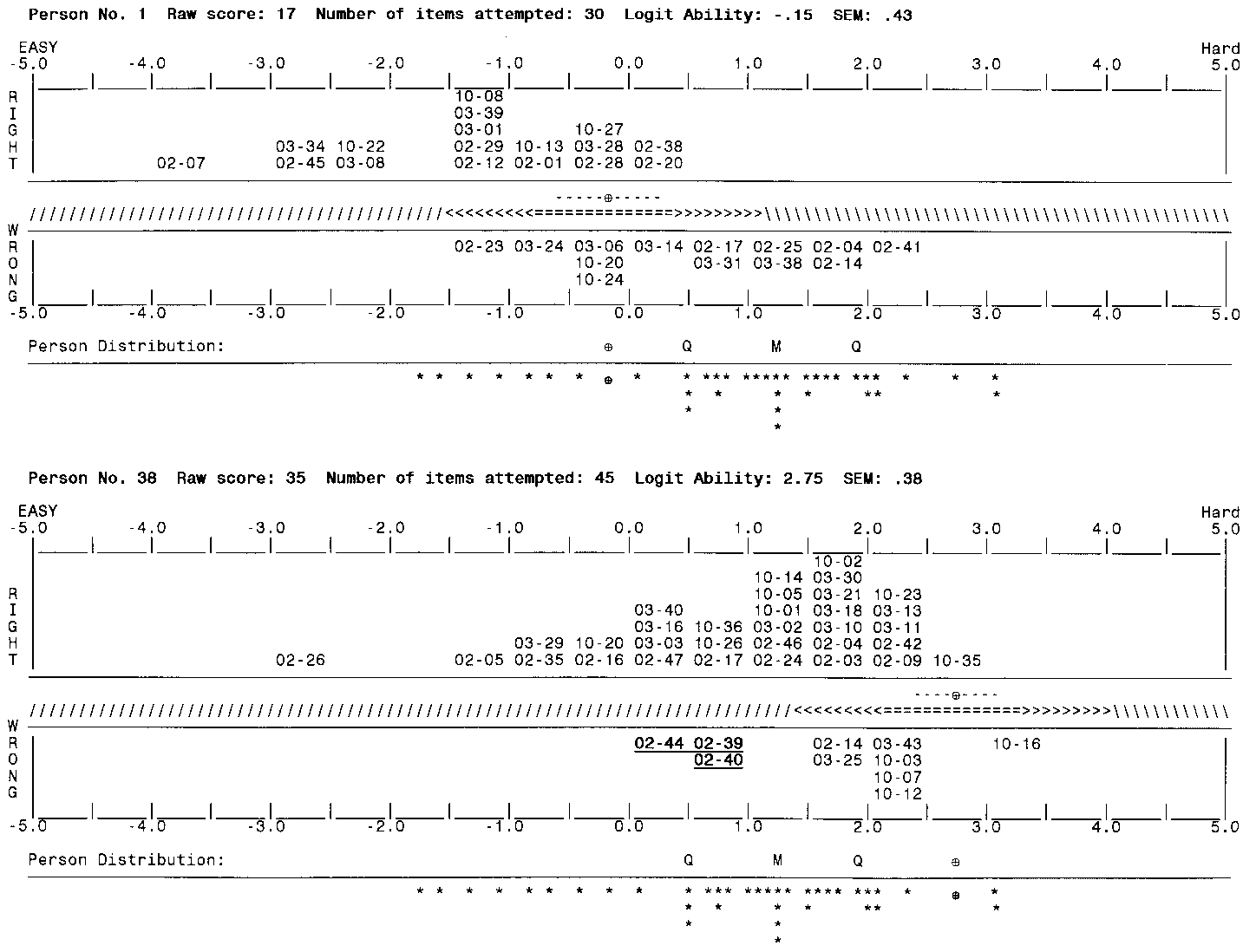
Abbreviated versions of two person maps are shown. The top of each map summarizes the person's test performance: raw score, number of items attempted, logit ability, and standard error of measurement. Conventionally, the center of the scale, 0.0, represents the average item difficulty for the bank of test items. In practice, logits are usually rescaled into positive integers for published reports.
The center section of each map shows item level performance. The items answered correctly are shown in the top half, those answered incorrectly in the bottom half. Items are identified by five character item names supplied by the user. Here, item names are textbook chapter numbers followed by objectives within chapters.
The band that separates the correct and incorrect responses indicates the person's ability estimate by "®" with a ±1 standard error band around that estimated ability indicated by "-".
The line of symbols beneath the ability estimate indicates the expected success rate for this examinee. The probabilities of correctly answering an item in the indicated ranges are: 80%-100%: "///", 65%-80%: "<lt;lt;", 35%-65%: "===", 20%-35%: ">gt;gt;", 0%-20%:"\\\". These symbols provide a frame of reference for the person's mastery of the material and for the consistency (fit) of the person's performance.
The histogram below the item section shows the performance of all persons taking the examination. Each "*" represents one person. This provides a normative interpretation of the measure.
In the first example, Person 1 has a low score, falling in the lower quartile of the class performance. The CAT test covered a wide range of item difficulties, from -4.0 to +2.0 logits. There were no surprising responses. The map of wrong responses shows what objectives this person missed and forms a guide for further study.
In the second example, Person 38 has a much higher ability estimate, third in the class. This test also covers a wide range of item difficulties, -3.0 to +3.0 logits. Here there are three unexpected incorrect responses to what should be easy items for this person. Person 38 had more than an 80 percent chance of answering items 02-33, 02-39, and 02-40 correctly. It seems that even this able examinee would benefit from further study of parts of Chapter 2!
Richard M. Smith 1994 RMT 8:1 p. 344-5
Smith RM (1991) IPARM Computer Program. Chicago: MESA Press
Wright BD, Mead RJ, Ludlow LH (1980) KIDMAP: Person-by-Item Interaction Mapping. MESA Memorandum #29. Chicago: MESA Press
Reporting candidate performance on computer-adaptive tests. Smith RM. … Rasch Measurement Transactions, 1994, 8:1 p.344-5
| Forum | Rasch Measurement Forum to discuss any Rasch-related topic |
Go to Top of Page
Go to index of all Rasch Measurement Transactions
AERA members: Join the Rasch Measurement SIG and receive the printed version of RMT
Some back issues of RMT are available as bound volumes
Subscribe to Journal of Applied Measurement
Go to Institute for Objective Measurement Home Page. The Rasch Measurement SIG (AERA) thanks the Institute for Objective Measurement for inviting the publication of Rasch Measurement Transactions on the Institute's website, www.rasch.org.
| Coming Rasch-related Events | |
|---|---|
| May. 15 - June 12, 2026, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| June 19 - July 25, 2026, Fri.-Sat. | On-line workshop: Rasch Measurement - Further Topics (E. Smith, Winsteps), www.statistics.com |
| Aug. 31 - Sept 2 2026, Mon.-Wed. | In person: IMEKO TC1 Metrology Education and Training symposium, Klagenfurt, Austria www.photomet-edumet2026.com. Submissions by April 20 |
| Aug. 30 - Sept. 3, 2027, Mon.-Fri. | In Person: 2027 IMEKO World Congress (TC1, Tc7, TC13, TC18, TC26), Rimini, Italy imeko2027.org |
The URL of this page is www.rasch.org/rmt/rmt81m.htm
Website: www.rasch.org/rmt/contents.htm