Conventional Factor Analysis input xni is a test score, Likert rating or MCQ response of person
n to item i. Incommensurable origins and scales are reconciled by using
sample means and standard deviations to commensurate items:
| (1) |
This "equating" depends on complete data. When data are missing, they must be feigned or
incomplete persons or items deleted. The model for Factor 1 is:
| (2) |
The Factor 1 residual is:
| (3) |
Whether this residual is all error or contains other factors is unknown. To find out, the residual is
taken as the data for Factor 2. Matrices of decreasing residuals {{znij}} j=2,M are extracted in turn to
calculate the M factor model:
| (4) |
Optimal values for person and item vectors {unj} and {vij} for each Factor j in turn are found by
minimizing:
| (5) |
Decomposition to identify each Factor j is done by initializing at wnj=1 and iterating equations:
| (6) | |
Factor score wnj is the value predicted by Factor j's regression on "independent" variables i = 1,L with regression coefficients {vij}.
Problems with Factor Analysis of Observational Data:
1. Since, data {{xni}} are never linear measures, Equations (2) and (3) cannot work in a reproducible way.
2. The necessity for complete data is awkward.
3. The residuals {{znij}} for seeking smaller factors are awash in turbulence left by preceding larger factors.
4. There is no way to know when to stop factoring.
5. Few algorithms provide standard errors for factor loadings or factor scores.
6. When old items are refactored from new data, factor sizes, loadings and number of factors change.
Most factor analysts can tolerate problems 1-5. Problem 6, however, is impossible to swallow. As analysts notice the numerical fragility of their structures, they abandon their person factor scores and ignore everything in the factor loadings except which factor gives each item its highest loading.
Person scores for these "same factor" clusters are obtained, not from factor scores, but by summing the standardized person responses zni1 to the clustered items.
Rasch Factor Analysis:
Since data {{xni}} are labels for ordinally interpreted qualities, we address them with a probability model
for ordered categories. For a dichotomy, we recognize xni=0,1 as a binomial. The error model which
follows is not the ill-chosen linear error model of factor analysis, but a binomial probability Pnix for the
occurrence of xni:
| (7) |
from which
Parameters, as with factor analysis (5), can be estimated by minimizing:
| (8) |
but now we get, not only least-square (maximum likelihood) estimates of linear person measures Bn
and linear item calibrations Di on their common variable, but also a stochastic basis, the binomial error
variances pni1pni0, for estimating useful standard errors and evaluating the probabilities of residuals:
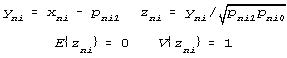 | (9) |
This enables detailed misfit analysis which, in turn, allows a partition of the matrix of residuals {{zni1}} into those many zni1 which are observed to be no greater than the probability model expects, say |zni1| < 2, and the subset of more extreme residuals, say |zni1| > 2 or 3, which are sufficiently improbable to invite investigation.
It is only when improbable residuals emerge that there is an incentive to look for a second variable. The improbable residuals tell us where to look. Should there be another useful variable in these data, it will be most evident among the responses to the subset of items and persons which misfit the first analysis.
To seek a second variable, therefore, we apply the probability model again, not to the whole matrix of residuals {{zni1}}, but only to the original ordinal responses {{xni}} to this subset of items. We estimate a new set of linear item calibrations {Di2} for these items, along with a new set of additive conjoint person measures {Bn2} on this newly defined "Variable 2". To find out whether Variable 2 is useful, we plot person measures {Bn2} against person measures {Bn1}. This plot will show us the extent to which we have found a useful second variable.
Benjamin D. Wright 1994 RMT 8:1 p. 348-9
Rasch factor analysis Wright BD. … Rasch Measurement Transactions, 1994, 8:1 p.348-9
| Forum | Rasch Measurement Forum to discuss any Rasch-related topic |
Go to Top of Page
Go to index of all Rasch Measurement Transactions
AERA members: Join the Rasch Measurement SIG and receive the printed version of RMT
Some back issues of RMT are available as bound volumes
Subscribe to Journal of Applied Measurement
Go to Institute for Objective Measurement Home Page. The Rasch Measurement SIG (AERA) thanks the Institute for Objective Measurement for inviting the publication of Rasch Measurement Transactions on the Institute's website, www.rasch.org.
| Coming Rasch-related Events | |
|---|---|
| May. 15 - June 12, 2026, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| June 19 - July 25, 2026, Fri.-Sat. | On-line workshop: Rasch Measurement - Further Topics (E. Smith, Winsteps), www.statistics.com |
| Aug. 31 - Sept 2 2026, Mon.-Wed. | In person: IMEKO TC1 Metrology Education and Training symposium, Klagenfurt, Austria www.photomet-edumet2026.com. Submissions by April 20 |
| Aug. 30 - Sept. 3, 2027, Mon.-Fri. | In Person: 2027 IMEKO World Congress (TC1, Tc7, TC13, TC18, TC26), Rimini, Italy imeko2027.org |
The URL of this page is www.rasch.org/rmt/rmt81q.htm
Website: www.rasch.org/rmt/contents.htm