Selecting data to answer a research question requires thought and care. Not all data are relevant. Some data may be misleading. In my study of physically-challenged patients, different subsets of the data address different research questions. Analyzing all data together masks the looked-for effects and complicates interpretation of results.
21 patients suffering from rheumatoid arthritis rated themselves on how difficult it was to perform 102 everyday activities. They were then given assistive devices (e.g., a cane for walking) or were taught alternative methods (e.g., using two hands, not just one). Then the 21 patients rerated the 102 activities. The research questions were (1) how much does the functioning of this type of patient improve, and (2) how much does each device or method assist each activity?
The patients rated themselves on a 0-4 scale, where 0 meant no difficulty and 4 extreme difficulty. Initial analysis indicated that the distinctions between 3 and 4 were idiosyncratic. To obtain more consistent results 4's were recoded as 3's.
There are two data sets: without devices and with devices. Analysis of the "no devices" data provides a measure for each patient's functioning without devices, and a calibration for each activity's difficulty without a device. The "with devices" data provides another measure for each patient and another calibration for each activity. But how are these to be compared? The devices not only make activities easier, but they also make the patients more able. Thus, neither person measures nor activity calibrations can be compared directly across these two analyses.
In order to provide a common frame of reference, the investigative analysis must be constrained so that the looked-for effect changes only one set of measures. The benchmark set of measures and calibrations is produced by the "no devices" data set. This gives a baseline measure for each patient, a baseline calibration for each activity, and also a baseline structure for the use of the rating scale (see diagram of analysis plan in Diagram).
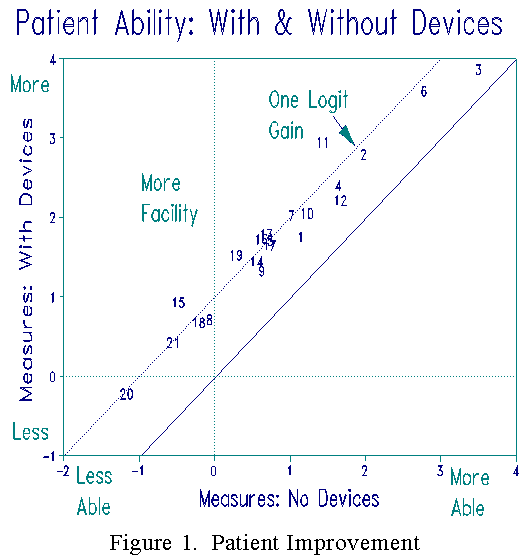
To discover how much the devices assisted these patients overall, all the effect of the devices must be focussed on the patients. To show this, the "with devices" data set is analyzed with the activity calibrations and rating scale structure anchored at their "no devices" baseline values. All changes are now forced into the new set of "with devices" patient measures. Figure 1 plots the "with device" against "no device" patient measures. My finding is that we can expect all patients to be helped about one logit, regardless of initial status.
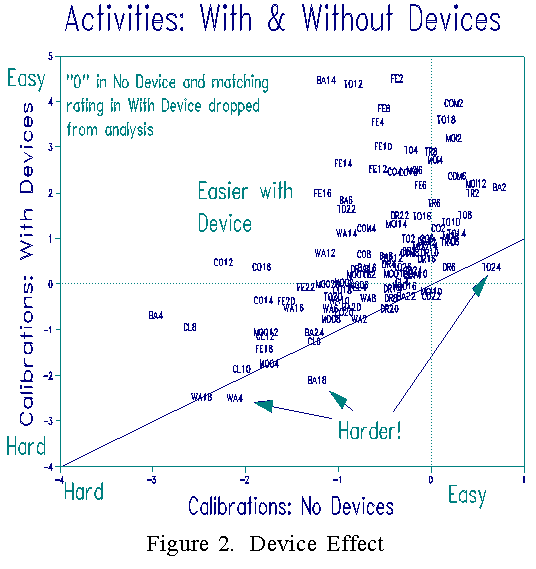
Next we wish to discover the effectiveness of each device. Whenever a patient reported a rating of 0, "no difficulty", initially without a device, no device is required, so no effect can be measured. To see the effect of each device clearly, we eliminated ratings given by patients for whom the device was irrelevant. To do this, we dropped all 0's in the "no device" data along with their corresponding ratings in the "with devices" data. Now we want to focus all of the device effects on the activities. This time it is the patient measures and rating scale structure that are anchored at their baseline "no device" values, i.e., the patients are asserted to perform at the same functional level regardless of the subsets of activities under consideration. Comparative analysis of the two reduced data sets now yields two calibrations for each activity, with and without device, also in the frame of reference set by the original benchmark calibration. These calibrations are plotted in Figure 2. Some devices are very effective. A few devices are hindrances! Device inventors can now see what works and what doesn't, and proceed accordingly.
Select relevant data! Nordenskiöld U. … Rasch Measurement Transactions, 1995, 9:3 p.444
| Forum | Rasch Measurement Forum to discuss any Rasch-related topic |
Go to Top of Page
Go to index of all Rasch Measurement Transactions
AERA members: Join the Rasch Measurement SIG and receive the printed version of RMT
Some back issues of RMT are available as bound volumes
Subscribe to Journal of Applied Measurement
Go to Institute for Objective Measurement Home Page. The Rasch Measurement SIG (AERA) thanks the Institute for Objective Measurement for inviting the publication of Rasch Measurement Transactions on the Institute's website, www.rasch.org.
| Coming Rasch-related Events | |
|---|---|
| May. 15 - June 12, 2026, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| June 19 - July 25, 2026, Fri.-Sat. | On-line workshop: Rasch Measurement - Further Topics (E. Smith, Winsteps), www.statistics.com |
| Aug. 31 - Sept 2 2026, Mon.-Wed. | In person: IMEKO TC1 Metrology Education and Training symposium, Klagenfurt, Austria www.photomet-edumet2026.com. Submissions by April 20 |
| Aug. 30 - Sept. 3, 2027, Mon.-Fri. | In Person: 2027 IMEKO World Congress (TC1, Tc7, TC13, TC18, TC26), Rimini, Italy imeko2027.org |
The URL of this page is www.rasch.org/rmt/rmt93e.htm
Website: www.rasch.org/rmt/contents.htm