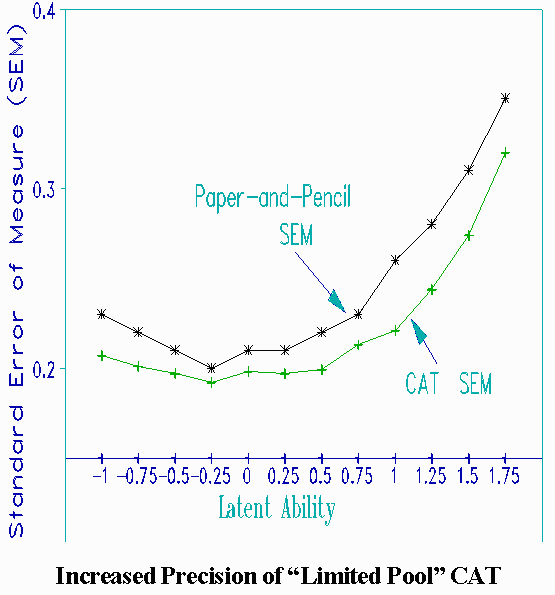
Is CAT worthwhile with a small item bank? We investigated this by comparing the accuracy and precision of measures obtained from a "limited" item bank with ones obtained when the same items were randomly selected and placed on one of four conventional test forms.
An examinee pool of 4494 examinees were administered one of four versions of a Calculations examination. After omitting misfitting items, the four forms consisted of 33, 35, or 36 items. There were 101 unique items which became the CAT item bank.
Using a Monte Carlo simulation, fifty hypothetical examinees with latent abilities ranging from -1.00 to +1.75 logits were administered 36 items from the 101 item bank. The latent ability range was chosen to match the conventional examination. Each administered item was the most on-target item not yet administered. (This strategy, forced on us by the limited bank, results in unbalanced use of the items and some examinees receiving similar tests.) The precision of the measures (SEM) were recorded after administration of 33, 35, and 36 items. These were compared with the SEM of the conventional tests of the same length. Since results for all comparisons were similar, only the 36 item comparisons are shown in the Figure.
Even with the limited item bank of only 101 items, 36 adaptively administered items yield noticeably more precise measures than 36 randomly selected items on a test form. The accuracy of CAT is also confirmed by the close match between the generating measures and their mean estimates; no difference was greater than .03 logits. The limited bank, however, does not contain enough items to measure examinees along the whole ability continuum with equal precision. For high performing examinees, the relevant part of the bank is exhausted before 36 items, so that items considerably off-target must be administered to these examinees. Nonetheless, because of efficient use of the available items, the largest improvement in precision is for high performers.
CAT with a limited item bank. Halkitis PN. … Rasch Measurement Transactions, 1996, 9:4 p.471
| Forum | Rasch Measurement Forum to discuss any Rasch-related topic |
Go to Top of Page
Go to index of all Rasch Measurement Transactions
AERA members: Join the Rasch Measurement SIG and receive the printed version of RMT
Some back issues of RMT are available as bound volumes
Subscribe to Journal of Applied Measurement
Go to Institute for Objective Measurement Home Page. The Rasch Measurement SIG (AERA) thanks the Institute for Objective Measurement for inviting the publication of Rasch Measurement Transactions on the Institute's website, www.rasch.org.
| Coming Rasch-related Events | |
|---|---|
| Jan. 16 - Feb. 13, 2025, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| Apr. 8 - Apr. 11, 2026, Wed.-Sat. | National Council for Measurement in Education - Los Angeles, CA, ncme.org/events/2026-annual-meeting |
| Apr. 8 - Apr. 12, 2026, Wed.-Sun. | American Educational Research Association - Los Angeles, CA, www.aera.net/AERA2026 |
| May. 15 - June 12, 2026, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| June 19 - July 25, 2026, Fri.-Sat. | On-line workshop: Rasch Measurement - Further Topics (E. Smith, Winsteps), www.statistics.com |
The URL of this page is www.rasch.org/rmt/rmt94m.htm
Website: www.rasch.org/rmt/contents.htm