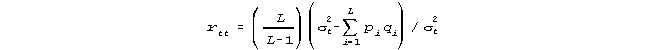
"The reliability of any set of measurements is logically defined as the proportion of their variance that is true variance... We think of the total variance of a set of measures as being made up of two kinds of variance: true variance and error variance... The true measure is assumed to be the genuine value of whatever is being measured." (Guilford, 1965, p. 488). So,
and, when measures and errors are uncorrelated,
Thus "reliability" is not an index of quality ("Is this a good measure of ...?"), but of relative reproducibility ("How repeatable is this measure?"). The most popular estimator of raw-score reliability is the Kuder-Richardson 20, a special case of Cronbach's Alpha:
where L is the length of the test, ²t is the variance of test raw scores across subjects, pi is the number of subjects who succeeded on item i, and qi is the number of subjects who failed. σ²t is the observed variance. pq estimates a binomial error variance. KR-20 is an index of the repeatability of raw scores, misinterpreted as linear measures.
The focal question is "Does this test produce repeatable measures for this sample?" The observed variance is of the Rasch measures. Each observation is modeled to include error:
![]()
Xni=0,1 is the response by subject n to item i. Pni is the probability that subject n would succeed on item i. Pni(1-Pni) is the binomial variance of an observation like Xni. The error variance of Rasch measures is estimated from the sum of the modeled variance of observations. This "model" error variance requires the data to conform stochastically to the Rasch model. Since there is always additional noise in the data, a more "real" error variance is:
"Real" error variance = model variance * MAX(1.0, INFIT mean-square)
Rasch reliability = (observed measure variance - "real" error variance) / observed measure variance
How does test targeting affect reliability? A test of 50 dichotomous items, uniformly distributed from -2 to +2 logits, was simulated on hypothetical samples of 1,000 subjects with abilities distributed, N(0,1). The sample was initially targeted on the test, then mistargeted one-half logit away from the test in five successive steps. This was repeated three times and their means reported.
For each targeting, KR-20 and "true" raw score S.D. were computed.
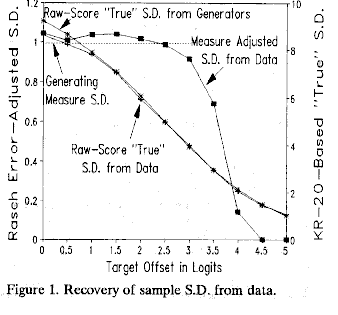
In Figure 1, the raw score S.D.s (using the right-hand Y-axis) are highly offset-dependent, but approximate the values predicted from the generating measures over the entire range.
For Rasch reliabilities, Adj. S.D. estimates the generator, "true", S.D.: Adj. S.D. = observed measure S.D. * (reliability). Zero and perfect scores were replaced by scores 0.5 score points more central, and the corresponding measures and standard errors imputed. In Figure 1, the success of the recovery of the generating measures from the simulated data is shown by the Adjusted S.D. curve. The recover is reasonably accurate with offsets in the range 0 to 3 logits.
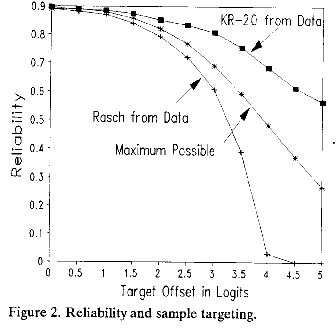 |
Rasch reliabilities can also be computed directly from the generating measures and item difficulties without data. These generator-based reliabilities are the maximum possible. Figure 2 plots all three reliability coefficients against the target offsets. As offset increases, the proportion of extreme scores increases and all reliabilities decrease. Rasch data-based reliabilities are less than the generator-based reliabilities because (i) measures are estimated from discrete (not continuous) raw scores; (ii) measures for extreme scores are biased towards the test center as targeting becomes more offset; (iii) Rasch S.E.s are INFIT-inflated, (but this is a minor effect). Thus Rasch data-based reliability understates measure reliability, providing assurance that a test has performed at least as well as Rasch "real" reliability.
KR-20 (Cronbach Alpha) always exceeds the maximum reliability possible for the measures underlying these simulated data. This misleads the test-user into believing a test has better measurement characteristics than it actually has. Yet KR-20 has met its design criteria, because estimated raw-score "true" S.D.s in Figure 1 match their predicted values. It reports the reliability of raw scores accurately, but these are local, test-dependent rankings. KR-20 overstates the reliability of the test-independent, generalizable measures the test is intended to imply. For inference beyond the test, Rasch reliability is more conservative and less misleading.
There is much more at RMT 13:2 Relating Cronbach and Rasch Reliabilities
John M. Linacre
Guilford J.P. (1965) Fundamental Statistics in Psychology and Education. New York: McGraw-Hill.
KR-20 / Cronbach Alpha or Rasch Person Reliability: Which Tells the "Truth"? Linacre J.M. … Rasch Measurement Transactions, 1997, 11:3 p. 580-1
| Forum | Rasch Measurement Forum to discuss any Rasch-related topic |
Go to Top of Page
Go to index of all Rasch Measurement Transactions
AERA members: Join the Rasch Measurement SIG and receive the printed version of RMT
Some back issues of RMT are available as bound volumes
Subscribe to Journal of Applied Measurement
Go to Institute for Objective Measurement Home Page. The Rasch Measurement SIG (AERA) thanks the Institute for Objective Measurement for inviting the publication of Rasch Measurement Transactions on the Institute's website, www.rasch.org.
| Coming Rasch-related Events | |
|---|---|
| May. 15 - June 12, 2026, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| June 19 - July 25, 2026, Fri.-Sat. | On-line workshop: Rasch Measurement - Further Topics (E. Smith, Winsteps), www.statistics.com |
| Aug. 31 - Sept 2 2026, Mon.-Wed. | In person: IMEKO TC1 Metrology Education and Training symposium, Klagenfurt, Austria www.photomet-edumet2026.com. Submissions by April 20 |
| Aug. 30 - Sept. 3, 2027, Mon.-Fri. | In Person: 2027 IMEKO World Congress (TC1, Tc7, TC13, TC18, TC26), Rimini, Italy imeko2027.org |
The URL of this page is www.rasch.org/rmt/rmt113l.htm
Website: www.rasch.org/rmt/contents.htm