
Differential item functioning (DIF) occurs when an item manifests a different level of difficulty with one group, the focal group, than with another, the reference group. This would seem simple to detect, but as Donoghue & Allen (D&A, 1993) point out, DIF detection requires the analyst to think!
Thin matching, thick matching and no matching
D&A examine the Mantel-Haenszel statistic, a simple odds estimator whose characteristics are identical to Rasch PROX DIF detection when the MH statistic works as intended (RMT 1989 3:2 51-53).
MH aggregates odds estimated from many two-by-two contingency tables, one table for each possible raw score on a test when "thin matching" is used. Each table has four cells: counts of subjects in reference and focal groups who succeed and fail on the item. D&A discover that MH malfunctions when cell counts are low. In fact, MH is incalculable when any cell count is zero. To avoid this, D&A investigate combining contingency tables (accumulating cell counts) into score group strata, i.e., "thick matching". Unfortunately, they are unable to specify a clearly superior thick matching method. Their endeavors remind us that the mindless application of any method invites confusion.
Rasch DIF detection is also based on odds estimation, but has the advantage that no matching or stratifying is needed. But Rasch techniques do require the analyst to think!
DIF and item dispersion
Construct a test from well-behaved items. Give the test to a reference group who perform in the intended way, and a focal group for whom some items may exhibit some degree of DIF. Calibrate the items on the two groups. Plot the item difficulty calibrations against each other. The slope of the best-fit line is not 1! The dispersion of the focal calibrations is greater than the reference calibrations! As Richard Smith pointed out to me, DIF affects item dispersion.
This mystified me. I simulated four data sets of 100 items and 500 people. One-fourth the people were in the focal group. One-fourth the items exhibited DIF against them. The DIF introduced in the four data sets was .5 logits, 1.0 logits, 1.5 logits, and 2.0 logits. The generating item difficulties were distributed uniformly [-2,2] resulting in expected item standard deviation of 1.2 logits for the reference group. The Table shows the standard deviations of the expected and estimated item difficulties for the four data sets.
| Standard Deviations of Item Difficulties | ||||
| Reference Group | Focal Group | |||
| DIF | Gen. | Est. | Gen. | Est. |
| 0.5 1.0 1.5 2.0 | 1.17 1.17 1.17 1.17 | 1.16 1.16 1.15 1.17 | 1.18 1.23 1.32 1.43 | 1.24 1.25 1.39 1.54 |
While the reference group calibrations do not spread out any more than the generated item difficulties, the focal group difficulties spread out considerably. The reason is immediately apparent. DIF provides additional difficulty to some items and so is an extra source of difficulty variance, inflating the item variance for the focal group.
If the number of people in the focal group is small, so that item calibration standard errors are large, then DIF may not appear as statistically significant item difficulty shifts. But it will still be seen as a difference in the dispersion of the two sets of item difficulties.
Where's the DIF?
As the number of DIF-affected items increase, the test items form two clusters: items with DIF and items without DIF. When comparisons are made with "average" item difficulties, it will seem that some items now exhibit DIF against the focal group, and some DIF against the reference group. If the groups are large enough, both sets of items will be reported as significantly biased! Where's the DIF?
This effect was reported years ago when calculators were introduced into classrooms. The focal group had calculators and found simple math problems easier. Items were reported to have DIF both against and in favor of the focal group. A little thought, however, reveals that virtually all DIF must be in favor of the focal group, and against the reference group!
|
|
|
|
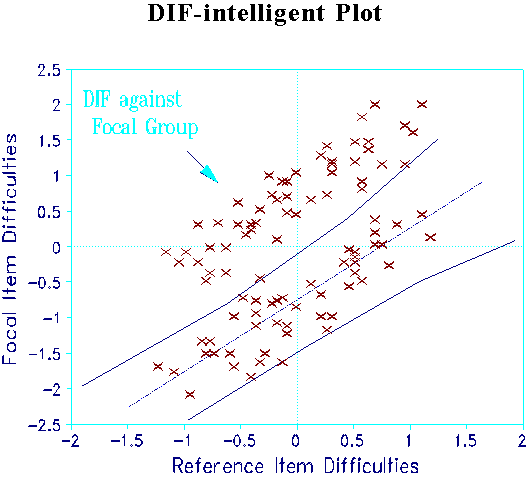
So I performed another simulation: 100 items and 250 people in which 50% of the items exhibit 1.5 logits of DIF against the focal group which contains 50% of the people. The standard deviation of the item difficulties for the reference group was 0.6 logits, for the focal group 1.0 logits. I have plotted the familiar control line plot with the identity line drawn through the average of the item difficulties. Notice that in addition to the DIF in the upper left quadrant, some items lie outside the control lines in the bottom right and show DIF in favor of the focal group!
In the second plot, the analyst has thought about the substance of the test and repositioned the identity line through the mean of the items chosen to manifest no DIF. Control lines are redrawn accordingly. This plot shows clearly two sets of items: DIF items in the upper left, and items without DIF within the control lines. This simple stratagem is beyond even the most thoughtful MH analysis.
Stuart Luppescu
Donoghue J.R., Allen N.L. (1993) Thin versus thick matching in the Mantel-Haenszel procedure for detecting DIF. Journal of Educational Statistics 18(2) 131-154.
Later note: This suggests that the maxim, "The item with the largest DIF is the one with the real (as opposed to artificial) DIF" (Andrich & Hagquist, 2012),
though useful is not definitive. The maxim implies that there is a unique reference point from which to measure DIF.
We can see that different choices of reference point will result in different items with the largest DIF and so
different items declared to have real DIF.
David Andrich and Curt Hagquist (2012) Real and Artificial Differential Item Functioning.
Journal of Educational and Behavioral Statistics, 37, 387-416.
Real and Artifical DIF detection examined: Which item has the real Differential Item Functioning?. Luppescu S. … Rasch Measurement Transactions, 1993, 7:2 p.285-6
| Forum | Rasch Measurement Forum to discuss any Rasch-related topic |
Go to Top of Page
Go to index of all Rasch Measurement Transactions
AERA members: Join the Rasch Measurement SIG and receive the printed version of RMT
Some back issues of RMT are available as bound volumes
Subscribe to Journal of Applied Measurement
Go to Institute for Objective Measurement Home Page. The Rasch Measurement SIG (AERA) thanks the Institute for Objective Measurement for inviting the publication of Rasch Measurement Transactions on the Institute's website, www.rasch.org.
| Coming Rasch-related Events | |
|---|---|
| May. 15 - June 12, 2026, Fri.-Fri. | On-line workshop: Rasch Measurement - Core Topics (E. Smith, Winsteps), www.statistics.com |
| June 19 - July 25, 2026, Fri.-Sat. | On-line workshop: Rasch Measurement - Further Topics (E. Smith, Winsteps), www.statistics.com |
| Aug. 31 - Sept 2 2026, Mon.-Wed. | In person: IMEKO TC1 Metrology Education and Training symposium, Klagenfurt, Austria www.photomet-edumet2026.com. Submissions by April 20 |
| Aug. 30 - Sept. 3, 2027, Mon.-Fri. | In Person: 2027 IMEKO World Congress (TC1, Tc7, TC13, TC18, TC26), Rimini, Italy imeko2027.org |
The URL of this page is www.rasch.org/rmt/rmt72b.htm
Website: www.rasch.org/rmt/contents.htm